CTC(Connectionist Temporal Classification) Loss 函数多用于序列有监督学习,优点是不需要对齐输入数据及标签。本文内容并不涉及CTC Loss的原理介绍,而是关于如何在Caffe中移植Baidu美研院实现的warp-ctc,并利用其实现一个LSTM + CTC Loss的验证码识别demo。下面这张图引用自warp-ctc的项目页面。本文介绍内容的相关代码可以参见我的GitHub项目warpctc-caffe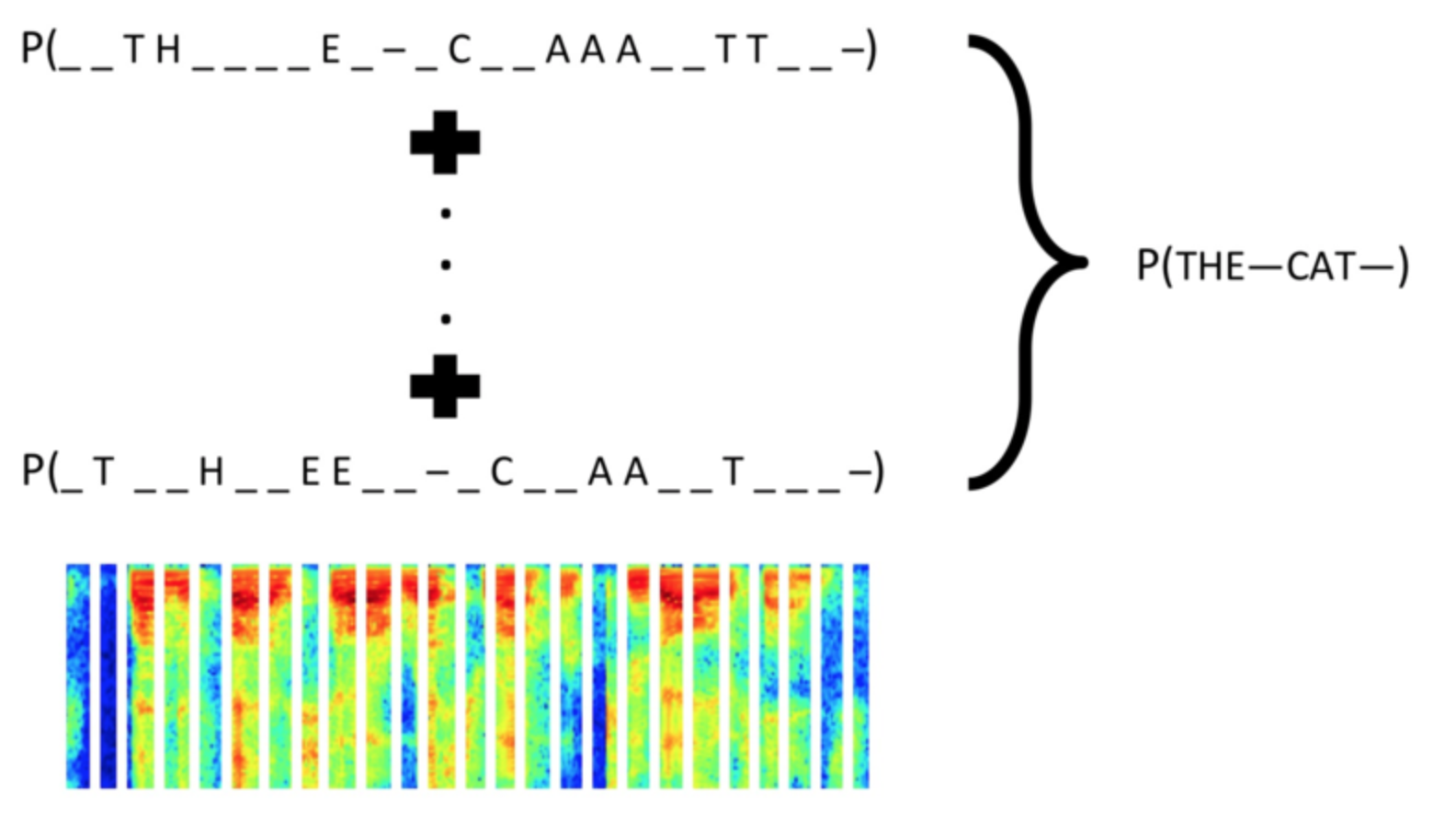
移植warp-ctc
本节介绍了如何将warp-ctc的源码在Caffe中进行编译。
首先,我们将warp-ctc的项目代码从GitHub上clone下来。在Caffe的include/caffe和src/caffe下分别创建名为3rdparty的文件夹,将warp-ctc中的头文件和实现文件分别放到对应的文件夹下。之后,我们需要对其代码和配置进行修改,才能在Caffe中顺利编译。
由于warp-ctc中使用了C++11的相关技术,所以需要修改Caffe的Makefile文件,添加C++11支持,可以参见Makefile。
对Caffe的修改就是这么简单,之后我们需要修改warp-ctc中的代码文件。这里的修改多且乱,边改边试着编译,所以可能其中也有不必要的修改。最后的目的就是能够使用GPU进行CTC Loss的计算。
warp-ctc提供了CPU多线程的计算,这里我直接将相应的openmp并行化语句删掉了。
另外,需要将warp-ctc中包含CUDA代码的相关头文件后缀名改为cuh,这样才能够通过编译。否则编译器会给出找不到__host__和__device__等等关键字的错误。
对于详细的修改配置,还请参见GitHub相应的代码文件。
实现CTC Loss计算
编译没有问题后,我们可以编写ctc_loss_layer实现CTC Loss的计算。在实现时,注意参考文件ctc.h。这个文件中给出了使用warp-ctc进行CTC Loss计算的全部API接口。
ctc_loss_layer继承自loss_layer,主要是前向和反向计算的实现。由于warp-ctc中只对单精度浮点数float进行支持,所以,对于双精度网络参数,直接将其设置为NOT_IMPLEMENTED,如下所示。
1 | template <> |
使用warp-ctc相关接口进行CTC Loss计算的步骤如下:
- 设置
ctcOptions,指定使用CPU或GPU进行计算,并指定CPU计算的线程数和GPU计算的CUDA stream。 - 调用
get_workspace_size()函数,预先为计算分配空间(分配的内存根据计算平台不同位于CPU或GPU)。 - 调用
compute_ctc_loss()函数,计算loss和gradient。
其中,在第三步中计算gradient时,可以直接将对应blob的cpu/gpu_diff指针传入,作为gradient。
这部分的实现代码分别位于include/caffe/layers和src/caffe/layers/下。
验证码数字识别
本部分相关代码位于examples/warpctc文件夹下。实验方案如下。
- 使用
Python中的capycha进行包含0-9数字的验证码图片的产生,图片中数字个数从1到MAX_LEN不等。 - 使用
10作为blank_label,将所有的标签序列在后面补blank_label以达到同样的长度MAX_LEN。 - 将图像的每一列看做一个time step,网络模型使用
image data->2LSTM->fc->CTC Loss,简单粗暴。 - 模型训练过程中,数据输入使用
HDF5格式。
数据产生
使用captcha生成验证码图片。这里是一个简单的API demo。默认生成的图片大小为160x60。我们将其长宽缩小一半,使用80x30的彩色图片作为输入。
使用python中的h5py模块生成HDF5格式的数据文件。将全部图片分为两部分,80%作为训练集,20%作为验证集。
LSTM的输入
在Caffe中已经有了lstm_layer的实现。lstm_layer要求输入的序列blob为TxNx...,也就是说我们需要将输入的image进行转置。
Caffe中Batch的内存布局顺序为NxCxHxW。我们将图像中的每一列作为一个time step输入的$x$向量。所以,在代码中使用了liuwei的SSD工作中实现的permute_layer进行转置,将W维度放到最前方。与之对应的参数定义如下:
1 | layer { |
另外,LSTM需要第二个输入,用于指示时序信号的起始位置。在代码中,我新加入了一个名为ContinuationIndicator的layer,产生对应的time indicator序列。
训练
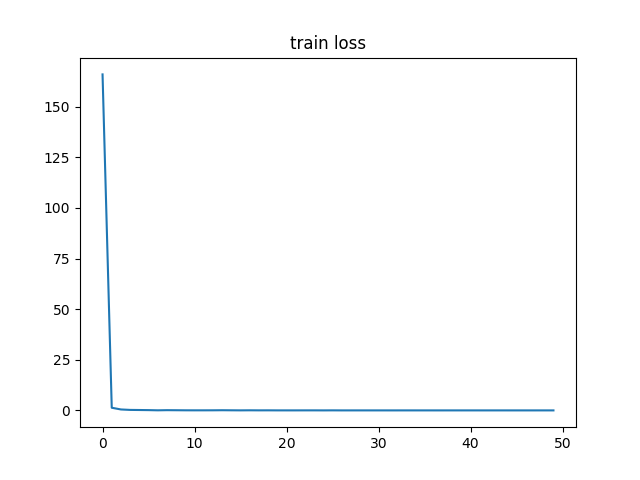
在某次试验中,迭代50,000次,实验过程中的损失函数变化如下:
在验证集上的精度变化如下:
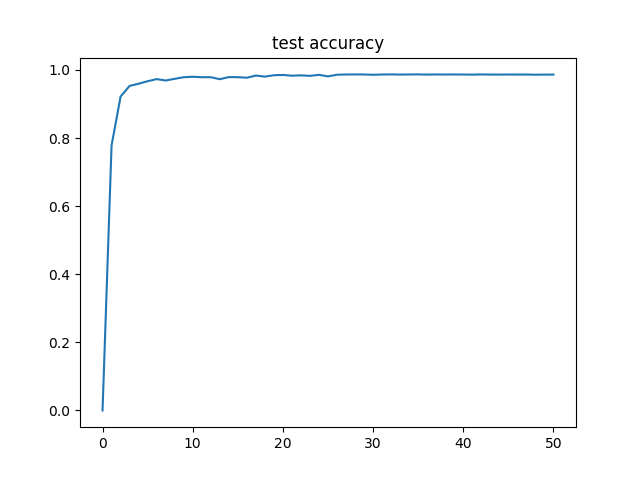
最终模型的精度在98%左右。考虑到本实验只是简单堆叠了两层的LSTM,并使用CTC Loss进行训练,能够轻易达到这一精度,可以在一定程度上说明CTC Loss的强大。
至于该实验的具体细节,可以参考repo的相关具体代码实现。