Focal Loss这篇文章是He Kaiming和RBG发表在ICCV2017上的文章。关于这篇文章在知乎上有相关的讨论。最近一直在做强化学习相关的东西,目标检测方面很长时间不看新的东西了,把自己阅读论文的要点记录如下,也是一次对这方面进展的回顾。
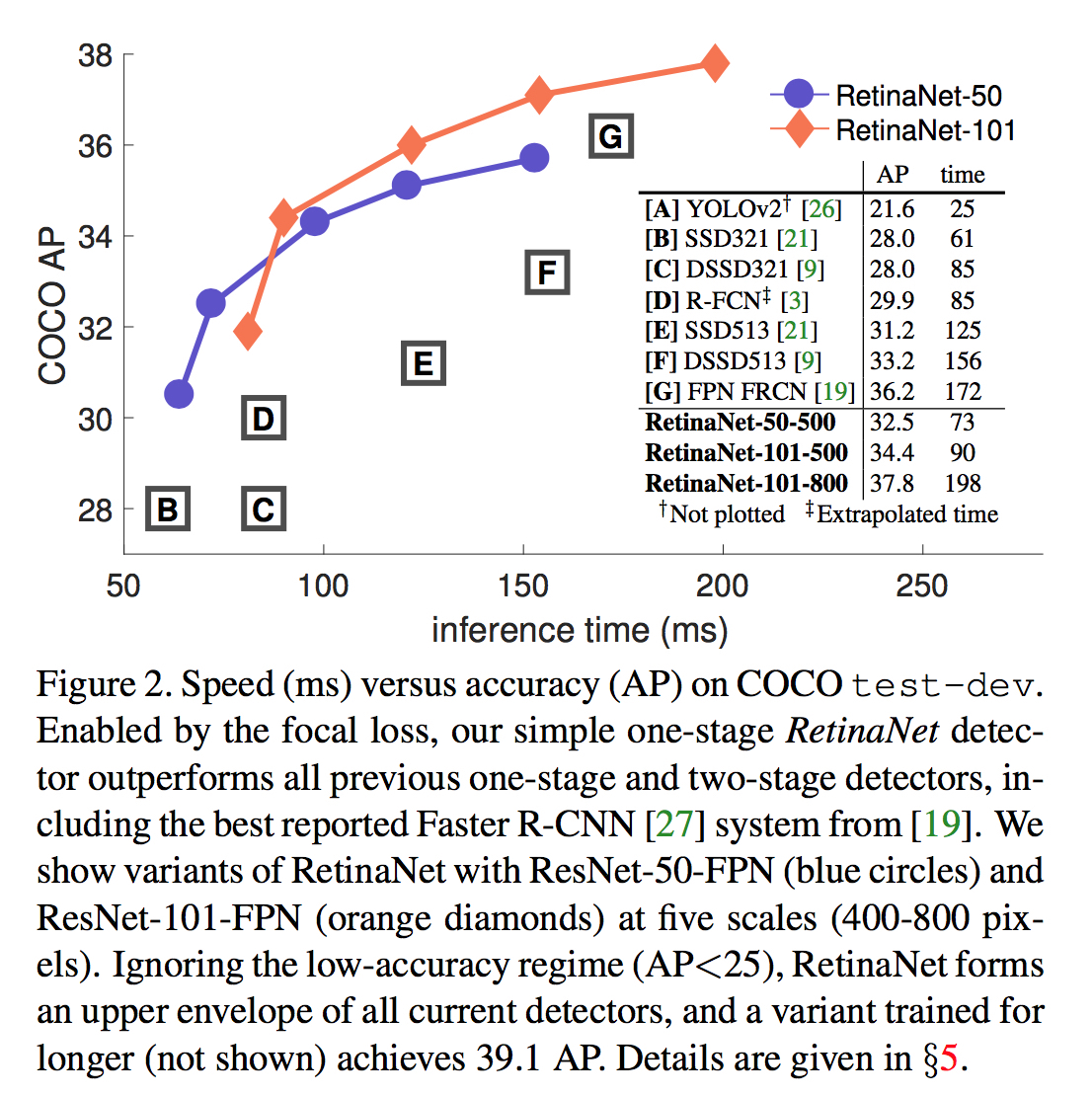
下图来自于论文,是各种主流模型的比较。其中横轴是前向推断的时间,纵轴是检测器的精度。作者提出的RetinaNet在单独某个维度上都可以吊打其他模型。不过图上没有加入YOLO的对比。YOLO的速度仍然是其一大优势,但是精度和其他方法相比,仍然不高。
Update@2018.03.26 YOLO更新了v3版本,见项目主页,并“点名”与有Focal Loss加持的Retina Net相比较,见下图。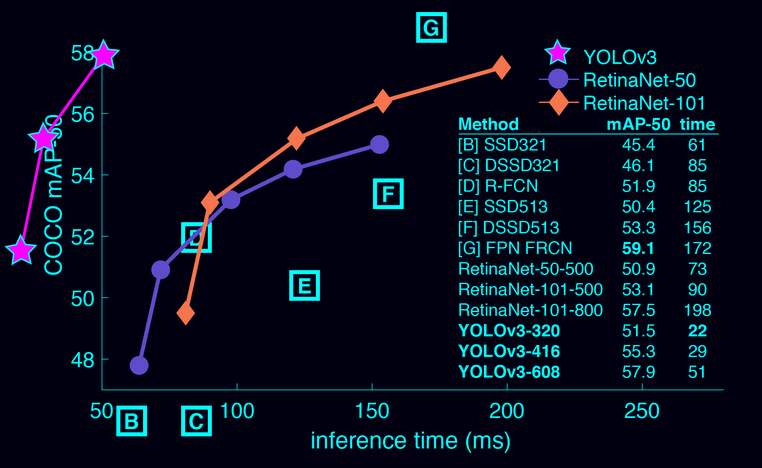
为什么要有Focal Loss?
目前主流的检测算法可以分为两类:one-state和two-stage。前者以YOLO和SSD为代表,后者以RCNN系列为代表。后者的特点是分类器是在一个稀疏的候选目标中进行分类(背景和对应类别),而这是通过前面的proposal过程实现的。例如Seletive Search或者RPN。相对于后者,这种方法是在一个稀疏集合内做分类。与之相反,前者是输出一个稠密的proposal,然后丢进分类器中,直接进行类别分类。后者使用的方法结构一般较为简单,速度较快,但是目前存在的问题是精度不高,普遍不如前者的方法。
论文作者指出,之所以做稠密分类的后者精度不够高,核心问题(central issus)是稠密proposal中前景和背景的极度不平衡。以我更熟悉的YOLO举例子,比如在PASCAL VOC数据集中,每张图片上标注的目标可能也就几个。但是YOLO V2最后一层的输出是$13 \times 13 \times 5$,也就是$845$个候选目标!大量(简单易区分)的负样本在loss中占据了很大比重,使得有用的loss不能回传回来。
基于此,作者将经典的交叉熵损失做了变形(见下),给那些易于被分类的简单例子小的权重,给不易区分的难例更大的权重。同时,作者提出了一个新的one-stage的检测器RetinaNet,达到了速度和精度很好地trade-off。
物体检测的两种主流方法
在深度学习之前,经典的物体检测方法为滑动窗,并使用人工设计的特征。HoG和DPM等方法是其中比较有名的。
R-CNN系的方法是目前最为流行的物体检测方法之一,同时也是目前精度最高的方法。在R-CNN系方法中,正负类别不平衡这个问题通过前面的proposal解决了。通过EdgeBoxes,Selective Search,DeepMask,RPN等方法,过滤掉了大多数的背景,实际传给后续网络的proposal的数量是比较少的(1-2K)。
在YOLO,SSD等方法中,需要直接对feature map的大量proposal(100K)进行检测,而且这些proposal很多都在feature map上重叠。大量的负样本带来两个问题:
- 过于简单,有效信息过少,使得训练效率低;
- 简单的负样本在训练过程中压倒性优势,使得模型发生退化。
在Faster-RCNN方法中,Huber Loss被用来降低outlier的影响(较大error的样本,也就是难例,传回来的梯度做了clipping,也只能是$1$)。而FocalLoss是对inner中简单的那些样本对loss的贡献进行限制。即使这些简单样本数量很多,也不让它们在训练中占到优势。
Focal Loss
Focal Loss从交叉熵损失而来。二分类的交叉熵损失如下:
对应的,多分类的交叉熵损失是这样的:
如下图所示,蓝色线为交叉熵损失函数随着$p_t$变化的曲线($p_t$意为ground truth,是标注类别所对应的概率)。可以看到,当概率大于$.5$,即认为是易分类的简单样本时,值仍然较大。这样,很多简单样本累加起来,就很可能盖住那些稀少的不易正确分类的类别。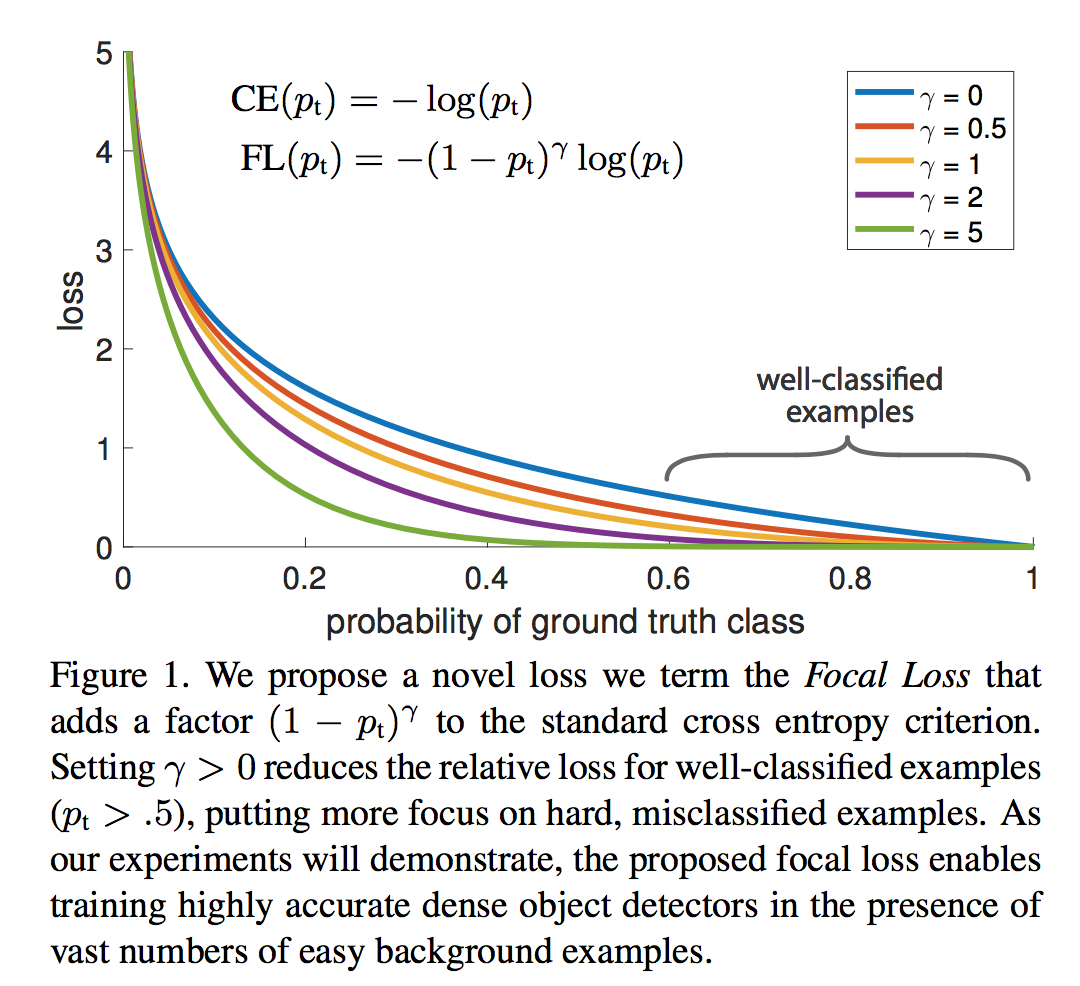
为了改善类别样本分布不均衡的问题,已经有人提出了使用加上权重的交叉熵损失,如下(即用参数$\alpha_t$来平衡,这组参数可以是超参数,也可以由类别的比例倒数决定)。作者将其作为比较的baseline。
作者提出的则是一个自适应调节的权重,即Focal Loss,定义如下。由上图可以看到$\gamma$取不同值的时候的函数值变化。作者发现,$\gamma=2$时能够获得最佳的效果提升。
在实际实验中,作者使用的是加权之后的Focal Loss,作者发现这样能够带来些微的性能提升。
实现
这里给出PyTorch中第三方给出的Focal Loss的实现。在下面的代码中,首先实现了one-hot编码,给定类别总数classes和当前类别index,生成one-hot向量。那么,Focal Loss可以用下面的式子计算(可以对照交叉损失熵使用onehot编码的计算)。其中,$\odot$表示element-wise乘法。
1 | import torch |
模型初始化
对于一般的分类网络,初始化之后,往往其输出的预测结果是均等的(随机猜测)。然而作者认为,这种初始化方式在类别极度不均衡的时候是有害的。作者提出,应该初始化模型参数,使得初始化之后,模型输出稀有类别的概率变小(如$0.01$)。作者发现这种初始化方法对于交叉熵损失和Focal Loss的性能提升都有帮助。
在后续的模型介绍部分,作者较为详细地说明了模型初始化方法。首先,从imagenet预训练得到的base net不做调整,新加入的卷积层权重均初始化为$\sigma=0.01$的高斯分布,偏置项为$0$。对于分类网络的最后一个卷积层,将偏置项置为$b=-\log((1-\pi)/\pi)$。这里的$\pi$参数是一个超参数,其意义是在训练的初始阶段,每个anchor被分类为前景的概率。在实验中,作者实际使用的大小是$0.01$。
这样进行模型初始化造成的结果就是,在初始阶段,不会产生大量的False Positive,使得训练更加稳定。
RetinaNet
作者利用前面介绍的发现和结论,基于ResNet和Feature Pyramid Net(FPN)设计了一种新的one-stage检测框架,命名为RetinaNet。(待续)