Han Song的Deep Compression是模型压缩方面很重要的论文。在Deep Compression中,作者提出了三个步骤来进行模型压缩:剪枝,量化和霍夫曼编码。其中,剪枝对应的方法就是基于本文要总结的这篇论文:Learning both Weights and Connections for Efficient Neural Networks。在这篇论文中,作者介绍了如何在不损失精度的前提下,对深度学习的网络模型进行剪枝,从而达到减小模型大小的目的。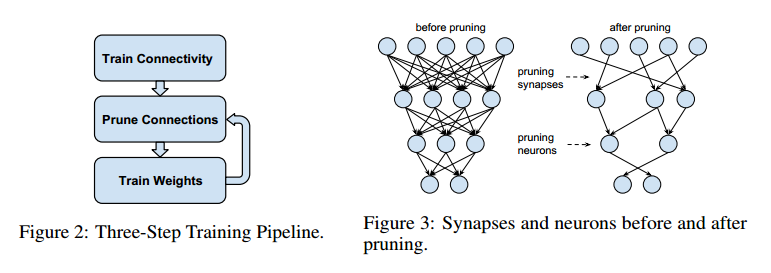
概述
DNN虽然能够解决很多以前很难解决的问题,但是一个应用方面的问题就是这些模型通常都太大了。尤其是当运行在手机等移动设备上时,对电源和网络带宽都是负担。对于电源来说,由于模型巨大,所以只能在外部内存DRAM中加载,造成能耗上升。具体数值见下表。所以模型压缩很有必要。本文就是使用剪枝的方法,将模型中不重要的权重设置为$0$,将原来的dense model转变为sparse model,达到压缩的目的。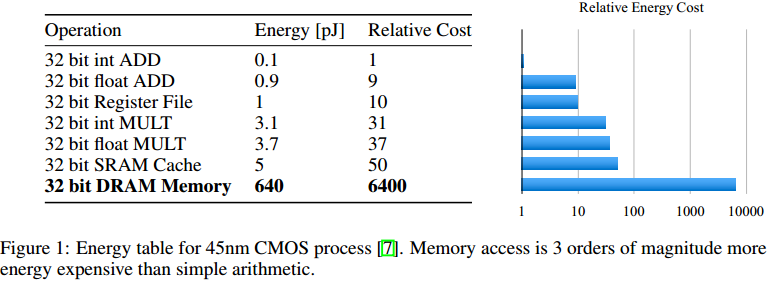
解决什么问题?
如何在不损失精度的前提下,对DNN进行剪枝(或者说稀疏化),从而压缩模型。
为什么剪枝是work的?
为什么能够通过剪枝的方法来压缩模型呢?难道剪掉的那些连接真的不重要到可以去掉吗?论文中,作者指出,DNN模型广泛存在着参数过多的问题,具有很大的冗余(见参考文献NIPS 2013的一篇文章Predicting parameters in deep learning)。
Neural networks are typically over-parameterized, and there is significant redundancy for deep learning models
另外,作者也为自己的剪枝方法找到了生理学上的依据,生理学上发现,对于哺乳动物来说,婴儿期会产生许多的突触连接,在后续的成长过程中,不怎么用的那些突出会退化消失。
怎么做
作者的方法分为三个步骤:
- Train Connectivity: 按照正常方法训练初始模型。作者认为该模型中权重的大小表征了其重要程度
- Prune Connection: 将初始模型中那些低于某个阈值的的权重参数置成$0$(即所谓剪枝)
- Re-Train: 重新训练,以期其他未被剪枝的权重能够补偿pruning带来的精度下降
为了达到一个满意的压缩比例和精度要求,$2$和$3$要重复多次。
相关工作
为了减少网络的冗余,减小模型的size,有以下相关工作:
- 定点化。将weight使用8bit定点表示,32bit浮点表示activation。
- 低秩近似。使用矩阵分解等方法。
- 网络设计上,NIN等使用Global Average Pooling取代FC层,可以大大减少参数量,这种结构已经得到了广泛使用。而FC也并非无用。在Pooling后面再接一个fc层,便于后续做迁移学习transfer learning。
- 从优化上下手,使用损失函数的Hessian矩阵,比直接用weight decay更好。
- HashedNet等工作,这里不再详述。
如何Prune
主要分为三步,上面 概述 中 怎么做 部分已经简单列出。下面的算法流程摘自作者的博士论文,可能更加详细清楚。
正则项的选择
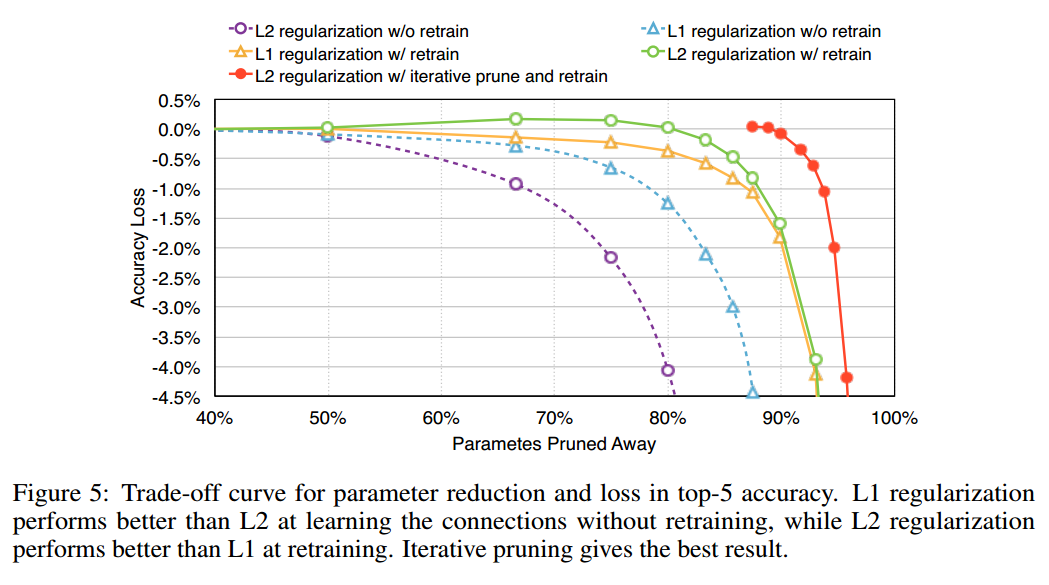
L1和L2都可以用来做正则,惩罚模型的复杂度。使用不同的正则方法会对pruning和retraining产生影响。实验发现,采用L2做正则项较好。见下图,可以看到详细的比较结果,分别是with/without retrain下L1和L2正则对精度的影响。还可以看到一个共性的地方,就是当pruning的比例大于某个阈值后,模型的精度会快速下降。
Dropout
Dropout是一项防止过拟合的技术。要注意的是,在retraining的时候,我们需要对Dropout ratio做出调整。因为网络中的很多连接都被剪枝剪下来了,所以dropout的比例要变小。下面给出定量的估计。
对于FC层来说,如果第$i$层的神经元个数是$N_i$,那么该层的连接数$C_i$用乘法原理可以很容易得到:$C_i = N_{i-1}N_i$。也就是说,连接数$C\sim N^2$。而dropout是作用于神经元的(dropout是将$N_i$个神经元输出按照概率dropout掉)。所以,比例$D^2 \sim C$,最后得到:
其中,下标$r$表示retraining,$o$表示初始模型(original)。
Local Pruning
在retraining部分,在初始模型基础上继续fine tune较好。为了能够更有效地训练,在训练FC层的时候,可以将CONV的参数固定住。反之亦然。
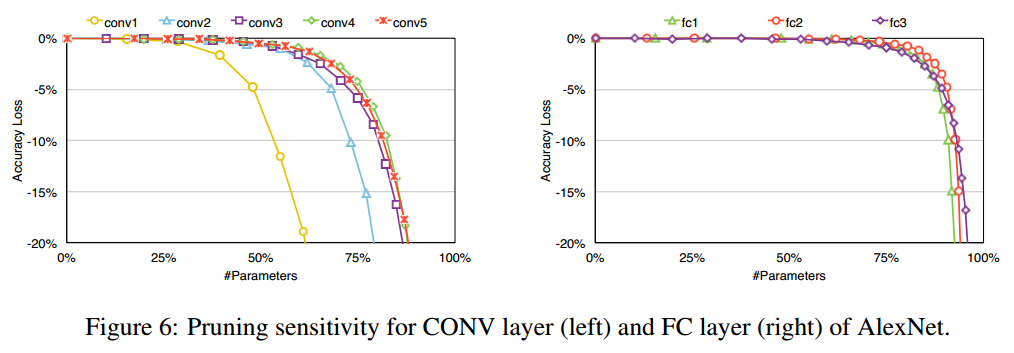
另外,不同深度和类型的layer对剪枝的敏感度是不一样的。作者指出,CONV比FC更敏感,第$1$个CONV比后面的要敏感。下图是AlexNet中各个layer剪枝比例和模型精度下降之间的关系。可以印证上面的结论。
多次迭代剪枝
应该迭代地进行多次剪枝 + 重新训练这套组合拳。作者还尝试过根据参数的绝对值依概率进行剪枝,效果不好。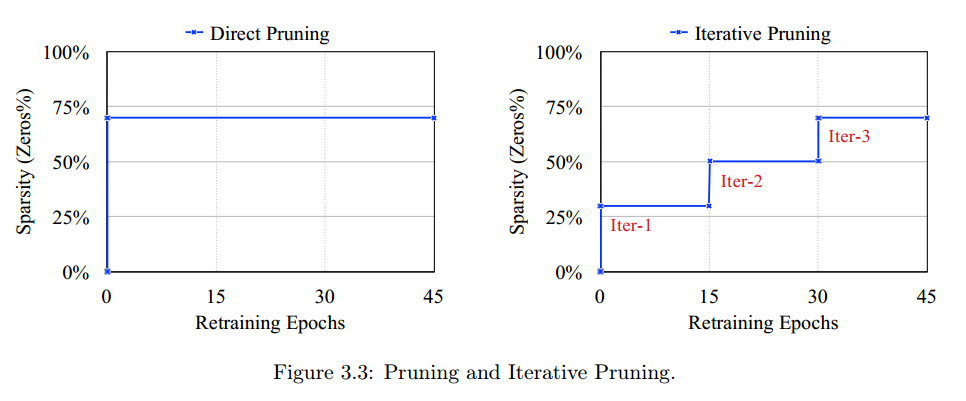
对神经元进行剪枝
将神经元之间的connection剪枝后(或者说将权重稀疏化了),那些$0$输入$0$输出的神经元也应该被剪枝了。然后,我们又可以继续以这个神经元出发,剪掉与它相关的connection。这个步骤可以在训练的时候自动发生。因为如果某个神经元已经是dead状态,那么它的梯度也会是$0$。那么只有正则项推着它向$0$的方向。
实验
使用Caffe实现,需要加入一个mask来表示剪枝。剪枝的阈值,是该layer的权重标准差乘上某个超参数。这里:Add pruning possibilities at inner_product_layer #4294 ,有人基于Caffe官方的repo给FC层加上了剪枝。这里:Github: DeepCompression,,有人实现了Deep Compression,可以参考他们的实现思路。
对于实验结果,论文中比对了LeNet和AlexNet。此外,作者的博士论文中给出了更加详细的实验结果,在更多的流行的模型上取得了不错的压缩比例。直接引用如下,做一个mark:
On the ImageNet dataset, the pruning method reduced the number of parameters of AlexNet by a factor of 9× (61 to 6.7 million), without incurring accuracy loss. Similar experiments with VGG-16 found that the total number of parameters can be reduced by 13× (138 to 10.3 million), again with no loss of accuracy. We also experimented with the more efficient fully-convolutional neural networks: GoogleNet (Inception-V1), SqueezeNet, and ResNet-50, which have zero or very thin fully connected layers. From these experiments we find that they share very similar pruning ratios before the accuracy drops: 70% of the parameters in those fully-convolutional neural networks can be pruned. GoogleNet is pruned from 7 million to 2 million parameters, SqueezeNet from 1.2 million to 0.38 million, and ResNet-50 from 25.5 million to 7.47 million, all with no loss of Top-1 and Top-5 accuracy on Imagenet.
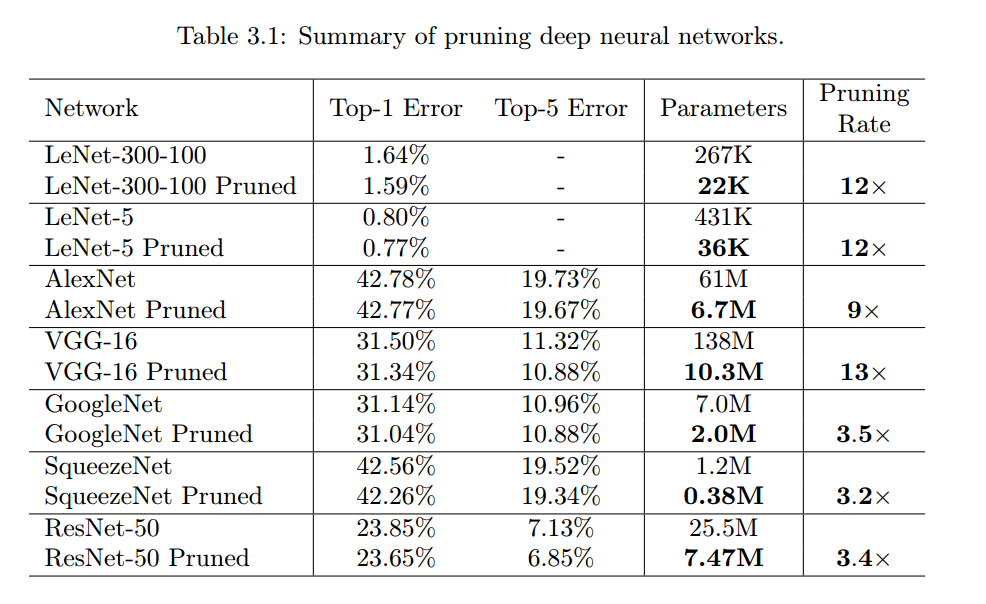
下面 参考资料 部分也给出了作者在GitHub上放出的Deep Compression的结果,可以前去参考。
学习率的设置
跑模型跑实验,一个重要的超参数就是学习率$LR$。这里作者也给了一个经验规律。一般在训练初始模型的时候,学习率都是逐渐下降的。刚开始是一个较大的值$LR_1$,最后是一个较小的值$LR_2$。它们之间可能有数量级的差别。作者指出,retraining的学习率应该介于两者之间。可以取做比$LR_1$小$1 \sim 2$个数量级。
RNN和LSTM
在博士论文中,作者还是用这一技术对RNN/LSTM在Neural Talk任务上做了剪枝,取得了不错的结果。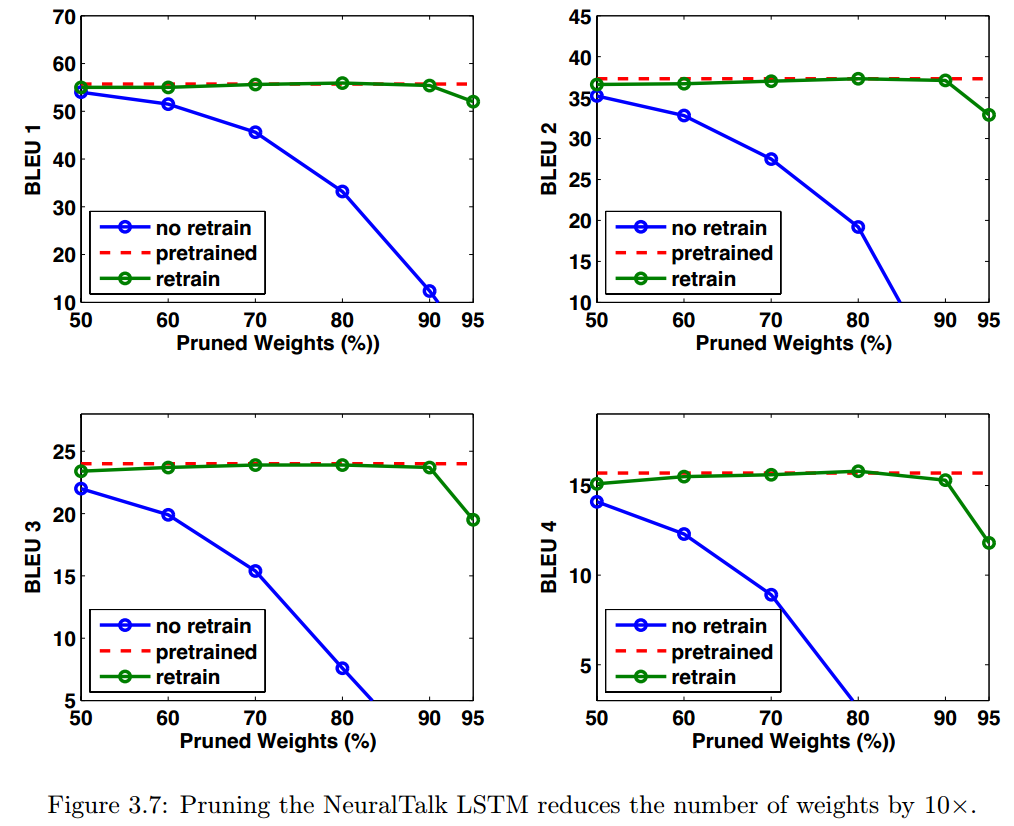
参考资料
- HanSong的个人主页:Homepage
- HanSong的博士论文:Efficient Methods and Hardware for Deep Learning
- 后续的Deep Compression论文:DEEP COMPRESSION- COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING
- Deep Compression AlexNet: Github: Deep-Compression-AlexNet