MobileNet是建立在Depthwise Separable Conv基础之上的一个轻量级网络。在本论文中,作者定量计算了使用这一技术带来的计算量节省,提出了MobileNet的结构,同时提出了两个简单的超参数,可以灵活地进行模型性能和inference时间的折中。后续改进的MobileNet v2以后讨论。
Depthwise Separable Conv
Depthwise Separable Conv把卷积操作拆成两个部分。第一部分,depthwise conv时,每个filter只在一个channel上进行操作。第二部分,pointwise conv是使用$1\times 1$的卷积核做channel上的combination。在Caffe等DL框架中,一般是设定卷积层的group参数,使其等于input的channel数来实现depthwise conv的。而pointwise conv和使用标准卷积并无不同,只是需要设置kernel size = 1。如下,是使用PyTorch的一个例子。
1 | def conv_dw(inp, oup, stride): |
这样做的好处就是能够大大减少计算量。假设原始conv的filter个数为$N$,kernel size大小为$D_k$,输入的维度为$D_F\times D_F\times M$,那么总的计算量是$D_K\times D_K\times M\times N\times D_F\times D_F$(设定stride=1,即输入输出的feature map在spatial两个维度上相同)。
改成上述Depthwise Separable Conv后,计算量变为两个独立操作之和,即$D_K\times D_K\times M\times D_F \times D_F + M\times N\times D_F\times D_F$,计算量是原来的$\frac{1}{N} + \frac{1}{D_K^2} < 1$。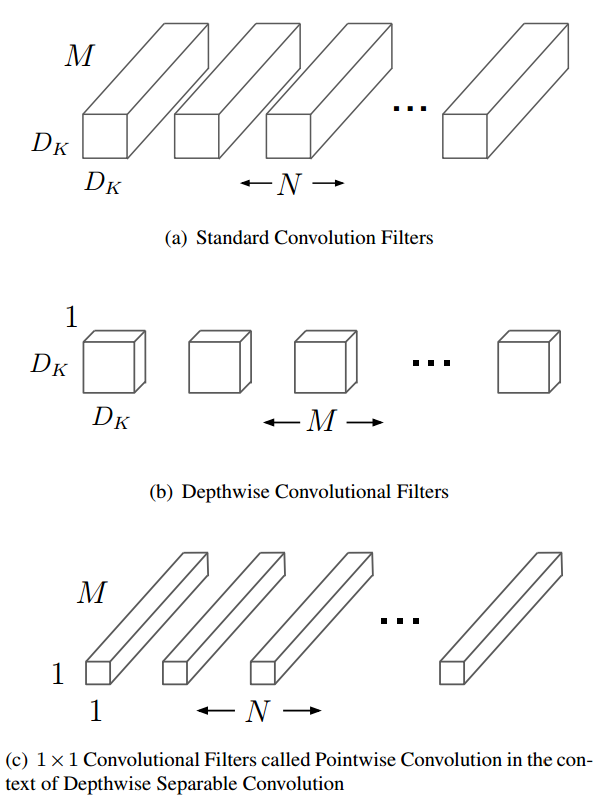
在实际使用时,我们在两个卷积操作之间加上BN和非线性变换层,如下图所示:
MobileNet
下图展示了如何使用Depthwise Separable Conv构建MobileNet。表中的dw表示depthwise conv,后面接的stride=1的conv即为pointwise conv。可以看到,网络就是这样的单元堆叠而成的。最后使用了一个全局的均值pooling,后面接上fc-1000来做分类。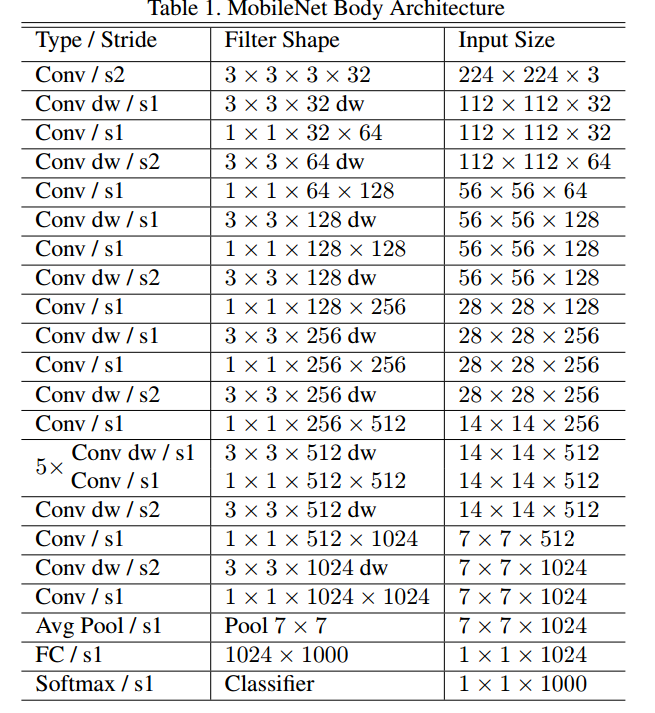
此外,作者指出目前的深度学习框架大多使用GEMM实现卷积层的计算(如Caffe等先使用im2col,再使用GEMM)。但是pointwis= conv其实不需要reordering,说明目前的框架这里还有提升的空间。(不清楚目前PyTorch,TensorFlow等对pointwise conv和depthwise conv的支持如何)
在训练的时候,一个注意的地方是,对depthwise conv layer,weight decay的参数要小,因为这层本来就没多少个参数。
这里,给出PyTorch的一个第三方实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18self.model = nn.Sequential(
conv_bn( 3, 32, 2),
conv_dw( 32, 64, 1),
conv_dw( 64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AvgPool2d(7),
)
self.fc = nn.Linear(1024, 1000)
网络设计超参数的影响
wider?or thinner?
描述网络,除了常见的深度,还有一个指标就是宽度。网络的宽度受filter个数的影响。更多的filter,说明网络更胖,提取feature的能力”看起来“就会越强。MobileNet使用一个超参数$\alpha$来实验。某个层的filter个数越多,带来的结果就是下一层filter的input channel会变多,$\alpha$就是前后input channel的数量比例。可以得到,计算量会大致变为原来的$\alpha^2$倍。
resolution
如果输入的spatial dimension变成原来的$\rho$倍,也就是$D_F$变了,那么会对计算量带来影响。利用上面总结的计算公式不难发现,和$\alpha$一样,计算量会变成原来的$\rho^2$倍。
实际中,我们令$\alpha$和$\rho$都小于$1$,构建了更少参数的mobilenet。下面是一个具体参数设置下,网络计算量和参数数目的变化情况。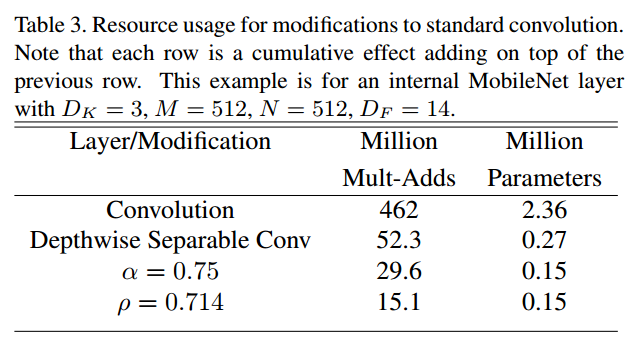
Depthwise Separable Conv真的可以?
同样的网络结构,区别在于使用/不使用Depthwise Separable Conv技术,在ImageNet上的精度相差很少(使用这一技术,下降了$1$个点),但是参数和计算量却节省了很多。
更浅的网络还是更瘦的网络
如果我们要缩减网络的参数,是更浅的网络更好,还是更瘦的网络更好呢?作者设计了参数和计算量相近的两个网络进行了比较,结论是相对而言,缩减网络深度不是个好主意。
alpha和rho的定量影响
定量地比较了不同$\alpha$和$\rho$的设置下,网络的性能。$\alpha$越小,网络精度越低,而且下降速度是加快的。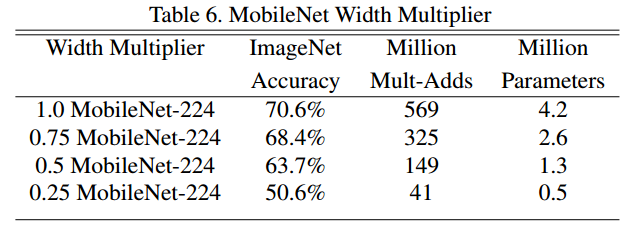
输入图像的resolution越小,网络精度也越低。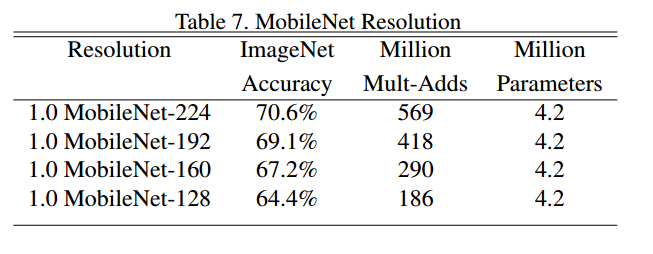
和其他网络的对比
这里只贴出结果。一个值得注意的地方是,SqueezeNet虽然参数很少,但是计算量却很大。而MobileNet可以达到参数也很少。这是通过depthwise separable conv带来的好处。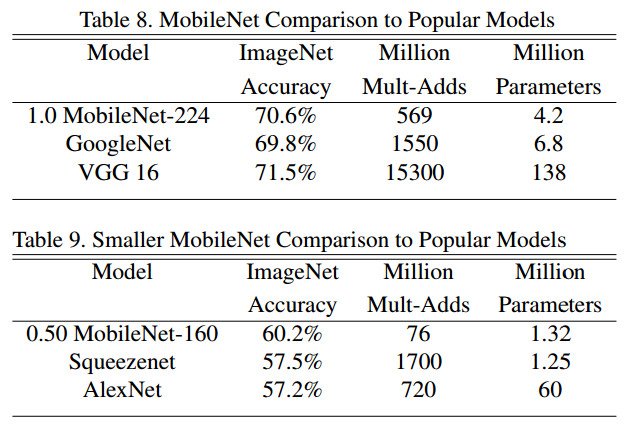
应用
接下来,论文讨论了MobileNet在多种不同任务上的表现,证明了它的泛化能力和良好表现。可以在网上找到很多基于MobileNet的detection,classification等的开源项目代码,这里就不再多说了。