在MXNet中,Module提供了训练模型的方便接口。使用symbol将计算图建好之后,用Module包装一下,就可以通过fit()方法对其进行训练。当然,官方提供的接口一般只适合用来训练分类任务,如果是其他任务(如detection, segmentation等),单纯使用fit()接口就不太合适。这里把fit()代码梳理一下,也是为了后续方便在其基础上实现扩展,更好地用在自己的任务。
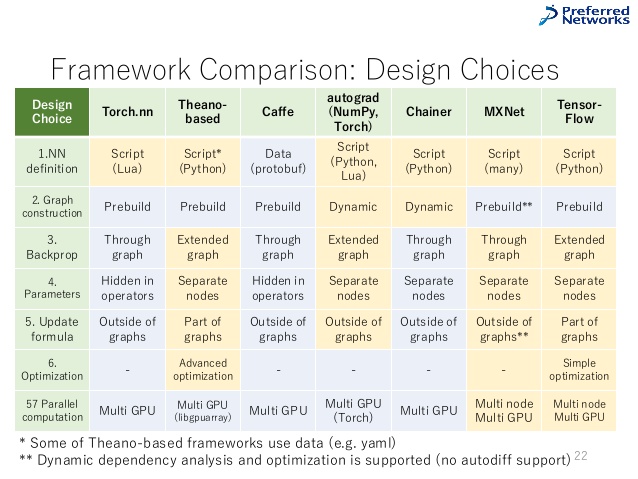
其实如果看开源代码数量的话,MXNet已经显得式微,远不如TensorFlow,PyTorch也早已经后来居上。不过据了解,很多公司内部都有基于MXNet自研的框架或平台工具。下面这张图来自LinkedIn上的一个Slide分享,姑且把它贴在下面,算是当前流行框架的一个比较(应该可以把Torch换成PyTorch)。
准备工作
首先,需要将数据绑定到计算图上,并初始化模型的参数,并初始化求解器。这些是求解模型必不可少的。
其次,还会建立训练的metric,方便我们掌握训练进程和当前模型在训练任务的表现。
这些是在为后续迭代进行梯度下降更新做准备。
迭代更新
使用SGD进行训练的时候,我们需要不停地从数据迭代器中获取包含data和label的batch,并将其feed到网络模型中。进行forward computing后进行bp,获得梯度,并根据具体的优化方法(SGD, SGD with momentum, RMSprop等)进行参数更新。
这部分可以抽成:1
2
3
4
5
6
7
8
9
10# in an epoch
while not end_epoch:
batch = next(train_iter)
m.forward_backward(batch)
m.update()
try:
next_batch = next(data_iter)
m.prepare(next_batch)
except StopIteration:
end_epoch = True
metric
在训练的时候,观察输出的各种metric是必不可少的。我们对训练过程的把握就是通过metric给出的信息。通常在分类任务中常用到的metric有Accuracy,TopK-Accuracy以及交叉熵损失等,这些已经在MXNet中有了现成的实现。而在fit中,调用了m.update_metric(eval_metric, data_batch.label)实现。这里的eval_metric就是我们指定的metric,而label是batch提供的label。注意,在MXNet中,label一般都是以list的形式给出(对应于多任务学习),也就是说这里的label是list of NDArray。当自己魔改的时候要注意。
logging
计算了eval_metric等信息,我们需要将其在屏幕上打印出来。MXNet中可以通过callback实现。另外,保存模型checkpoint这样的功能也是通过callback实现的。一种常用的场景是每过若干个batch,做一次logging,打印当前的metric信息,如交叉熵损失降到多少了,准确率提高到多少了等。MXNet会将以下信息打包成BatchEndParam类型(其实是一个自定义的namedtuple)的变量,包括当前epoch,当前迭代次数,评估的metric。如果你需要更多的信息或者更自由的logging监控,也可以参考代码自己实现。
我们以常用的Speedometer看一下如何使用这些信息,其功能如下,将训练的速度和metric打印出来。
Logs training speed and evaluation metrics periodically
PS:这里有个隐藏的坑。MXNet中的Speedometer每回调一次,会把metric的内容清除。这在训练的时候当然没问题。但是如果是在validation上跑,就会有问题了。这样最终得到的只是最后一个回调周期那些batch的metric,而不是整个验证集上的。如果在fit方法中传入了eval_batch_end_callback参数就要注意这个问题了。解决办法一是在Speedometer实例初始化时传入auto_reset=False,另一种干脆就不要加这个参数,默认为None好了。同样的问题也发生在调用Module.score()方法来获取模型在验证集上metric的时候。
可以在Speedometer代码中寻找下面这几行,会更清楚:
1 | if param.eval_metric is not None: |
在验证集上测试
当在训练集上跑过一个epoch后,如果提供了验证集的迭代器,会在验证集上对模型进行测试。这里,MXNet直接封装了score()方法。在score中,基本流程和fit()相同,只是我们只需要forward computing即可。
附
用了一段时间的MXNet,给我的最大的感觉是MXNet就像一个写计算图的前端,提供了很方便的python接口生成静态图,以及很多“可插拔”的插件(虽然可能不是很全,更像是一份guide而不是拿来即用的tool),如上文中的metric等,使其更适合做成流程化的基础DL平台,供给更上层方便地配置使用。缺点就是隐藏了比较多的实现细节(当然,你完全可以从代码中自己学习,比如从fit()代码了解神经网络的大致训练流程)。至于MXNet宣扬的诸如速度快,图优化,省计算资源等优点,因为我没有过数据对比,就不说了。
缺点就是写图的时候有时不太灵活(可能也是我写的看的还比较少),即使是和TensorFlow这种同为静态图的DL框架比。另外,貌似MXNet中很多东西都没有跟上最新的论文等,比如Cosine的learning rate decay就没有。Model Zoo也比较少(gluon可能会好一点,Gluon-CV和Gluon-NLP貌似是在搞一些论文复现的工作)。对开发来讲,很多东西都需要阅读代码才能知道是怎么回事,只是读文档的话容易踩坑。
说到这里,感觉MXNet的python训练接口(包括module,optimizer,metric等)更像是一份example代码,是在教你怎么去用MXNet,而不像一个灵活地强大的工具箱。当然,很多东西不能得兼,希望MXNet越来越好。