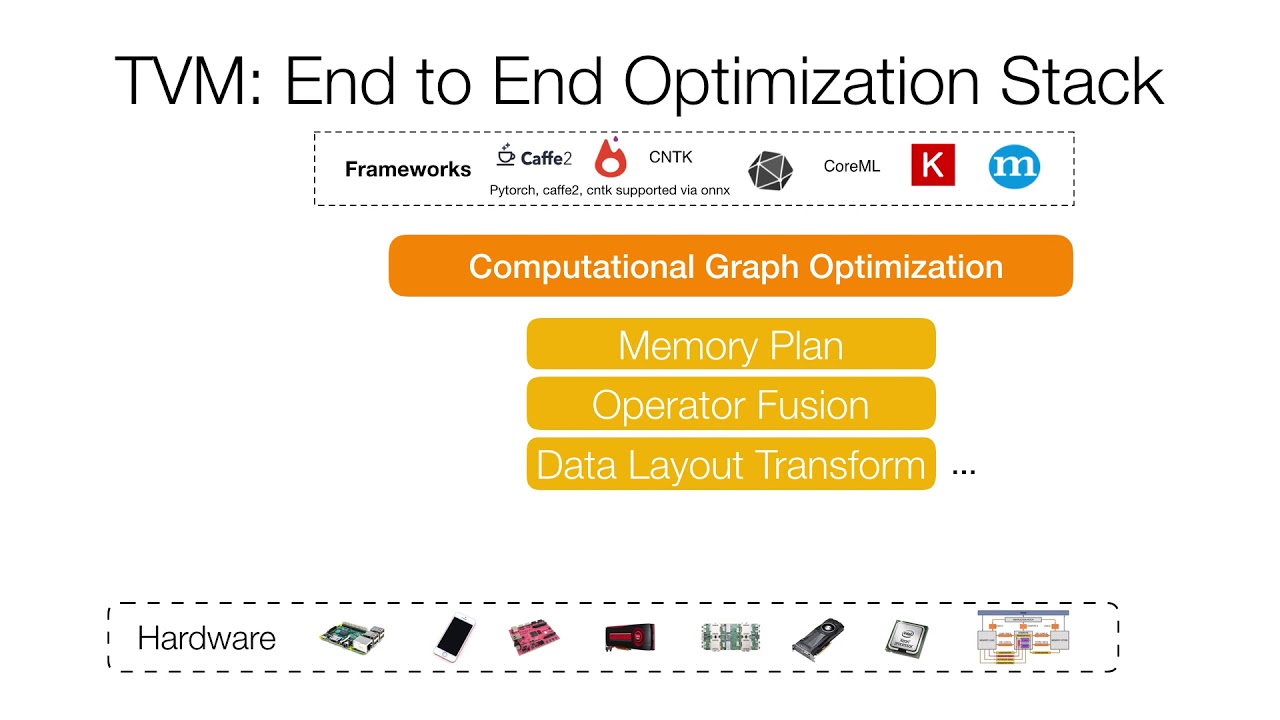
记录一个编译Caffe的坑。环境,Debian 9 + GCC 6.3.0,出现的问题:
1 | In file included from /usr/local/cuda/include/cuda_runtime.h:120:0, |
如果你和我一样,自从从Github clone Caffe后很长时间没有与master合并过,就有可能出现这个问题。
解决方法:这个问题应该是和boost有关,最初我看到的解决方法是将boost升级到1.65.1。不过感觉好麻烦,后来找到了这个github issue,修改include/caffe/common.hpp即可。