Blob是Caffe中的基本数据结构,类似于TensorFlow和PyTorch中的Tensor。图像读入后作为Blob,开始在各个Layer之间传递,最终得到输出。下面这张图展示了Blob和Layer之间的关系:
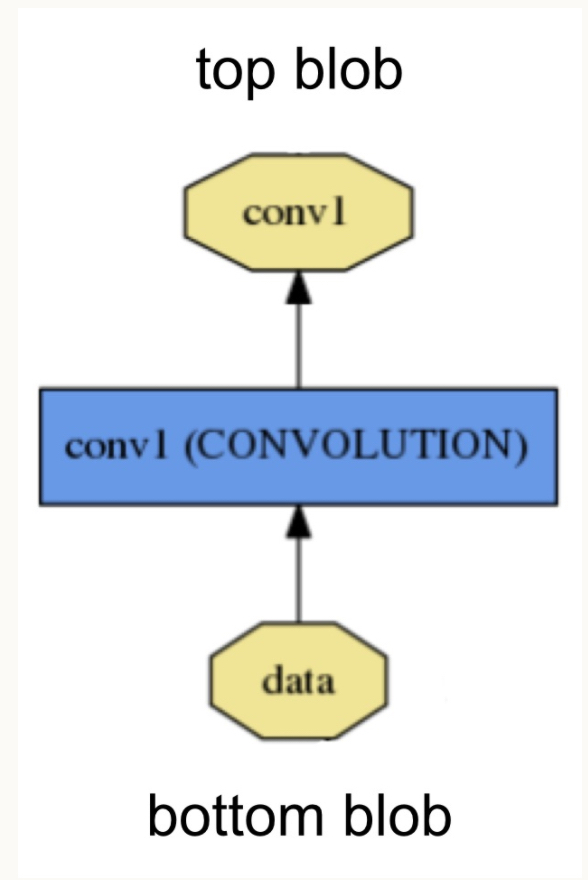
Caffe中的Blob在实现的时候,使用了SyncedMem管理内存,并在内存(Host)和显存(device)之间同步。这篇博客对Caffe中SyncedMem的实现做一总结。
SyncedMem的作用
Blob是一个多维的数组,可以位于内存,也可以位于显存(当使用GPU时)。一方面,我们需要对底层的内存进行管理,包括何何时开辟内存空间。另一方面,我们的训练数据常常是首先由硬盘读取到内存中,而训练又经常使用GPU,最终结果的保存或可视化又要求数据重新传回内存,所以涉及到Host和Device内存的同步问题。
同步的实现思路
在SyncedMem的实现代码中,作者使用一个枚举量head_来标记当前的状态。如下所示:
1 | // in SyncedMem |
这样,利用head_变量,就可以构建一个状态转移图,在不同状态切换时进行必要的同步操作等。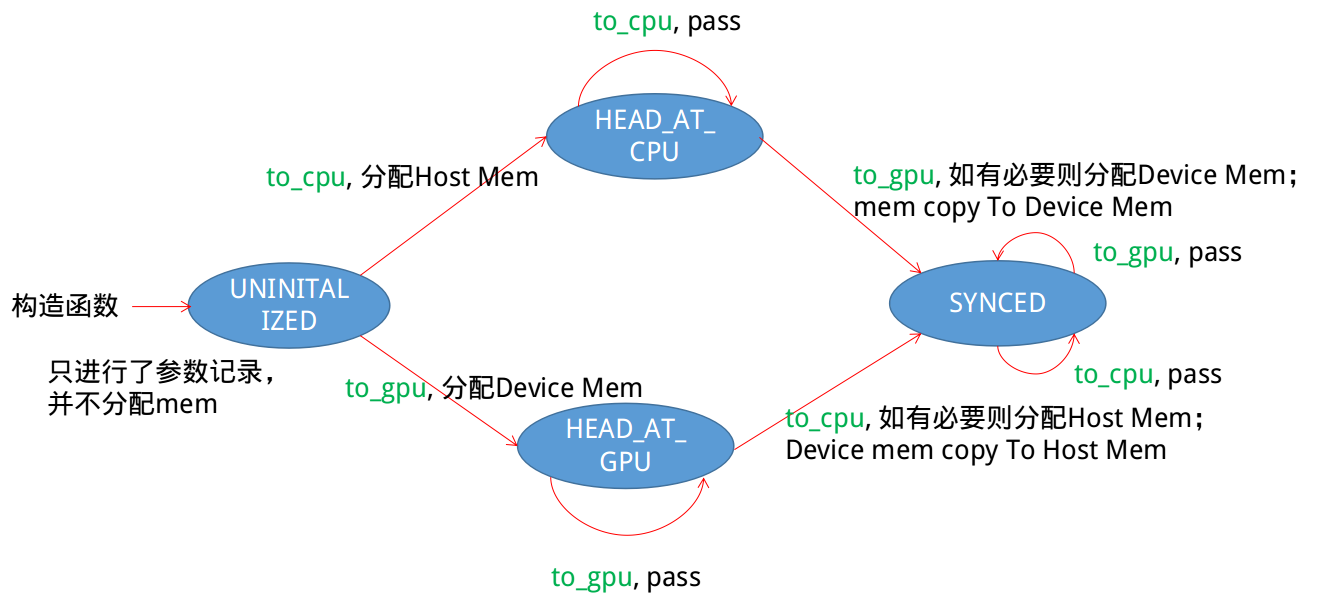
具体实现
SyncedMem的类声明如下:
1 | /** |
我们以to_cpu()为例,看一下如何在不同状态之间切换。
1 | inline void SyncedMemory::to_gpu() { |
注意到,除了head_以外,SyncedMemory中还有own_gpu_data_(同样,也有own_cpu_data_)的成员。这个变量是用来标志当前CPU或GPU上有没有分配内存,从而当我们使用set_c/gpu_data或析构函数被调用的时候,能够正确释放内存/显存的。