卷积神经网络虽然已经在很多任务上取得了很棒的效果,但是模型大小和运算量限制了它们在移动设备和嵌入式设备上的使用。模型量化压缩等问题自然引起了大家的关注。Incremental Network Quantization这篇文章关注的是如何使用更少的比特数进行模型参数量化以达到压缩模型,减少模型大小同时使得模型精度无损。如下图所示,使用5bit位数,INQ在多个模型上都取得了不逊于原始FP32模型的精度。实验结果还是很有说服力的。作者将其开源在了GitHub上,见Incremental-Network-Quantization。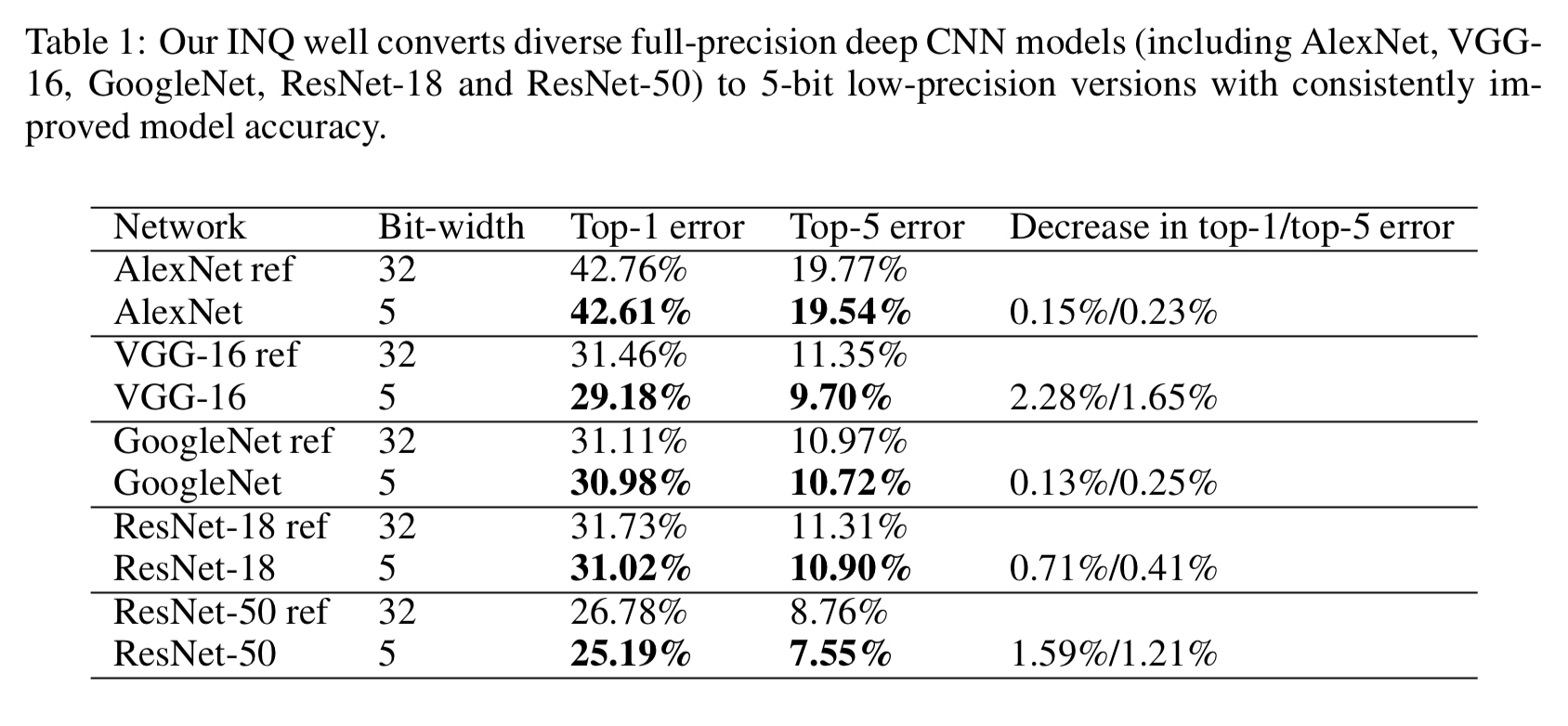
量化方法
INQ论文中,作者采用的量化方法是将权重量化为$2$的幂次或$0$。具体来说,是将权重$W_l$(表示第$l$层的参数权重)舍入到下面这个有限集合中的元素(在下面的讨论中,我们认为$n_1 > n_2$):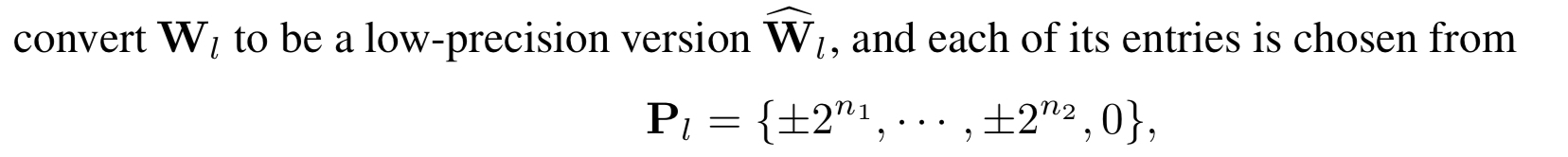
假设用$b$bit表示权重,我们分出$1$位单独表示$0$。
PS:这里插一句。关于为什么要单独分出$1$位表示$0$,毕竟这样浪费了($2^b$ vs $2^{b-1}+1$)。GitHub上有人发issue问,作者也没有正面回复这样做的原因。以我的理解,是方便判定$0$和移位。因为作者将权重都舍入到了$2$的幂次,那肯定是为了后续将乘法变成移位操作。而使用剩下的$b-1$表示,可以方便地读出移位的位数,进行操作。
这样,剩下的$b-1$位用来表示$2$的幂次。我们需要决定$n_1$和$n_2$。因为它俩决定了表示范围。它们之间的关系为:
其中,乘以$2$是考虑到正负对称的表示范围。
如何确定$n_1$呢(由上式可知,有了$b$和$n_1$,$n_2$就确定了)。作者考虑了待量化权重中的最大值,我们需要设置$n_1$,使其刚好不溢出。所以有:
其中,$s$是权重当中绝对值最大的那个,即$s = \max \vert W_l\vert$。
之后做最近舍入就可以了。对于小于最小分辨力$2^{n_2}$的那些权重,将其直接截断为$0$。
训练方法
量化完成后,网络的精度必然会下降。我们需要对其进行调整,使其精度能够恢复原始模型的水平。为此,作者提出了三个主要步骤,迭代地进行。即 weight partition(权重划分), group-wise quantization(分组量化) 和re-training(训练)。
re-training好理解,就是量化之后要继续做finetuning。前面两个名词解释如下:weight partition是指我们不是对整个权重一股脑地做量化,而是将其划分为两个不相交的集合。group-wise quantization是指对其中一个集合中的权重做量化,另一组集合中的权重不变,仍然为FP32。注意,在re-training中,我们只对没有量化的那组参数做参数更新。下面是论文中的表述。
Weight partition is to divide the weights in each layer of a pre-trained full-precision CNN model into two disjoint groups which play comple- mentary roles in our INQ. The weights in the first group are responsible for forming a low-precision base for the original model, thus they are quantized by using Equation (4). The weights in the second group adapt to compensate for the loss in model accuracy, thus they are the ones to be re-trained.
训练步骤可以用下图来表示。在第一个迭代中,将所有的权重划分为黑色和白色两个部分(图$1$)。黑色部分的权重进行量化,白色部分不变(图$2$)。然后,使用SGD更新那些白色部分的权重(图$3$)。在第二次迭代中,我们扩大量化权重的范围,重复进行迭代$1$中的操作。在后面的迭代中,以此类推,只不过要不断调大量化权重的比例,最终使得所有权重都量化为止。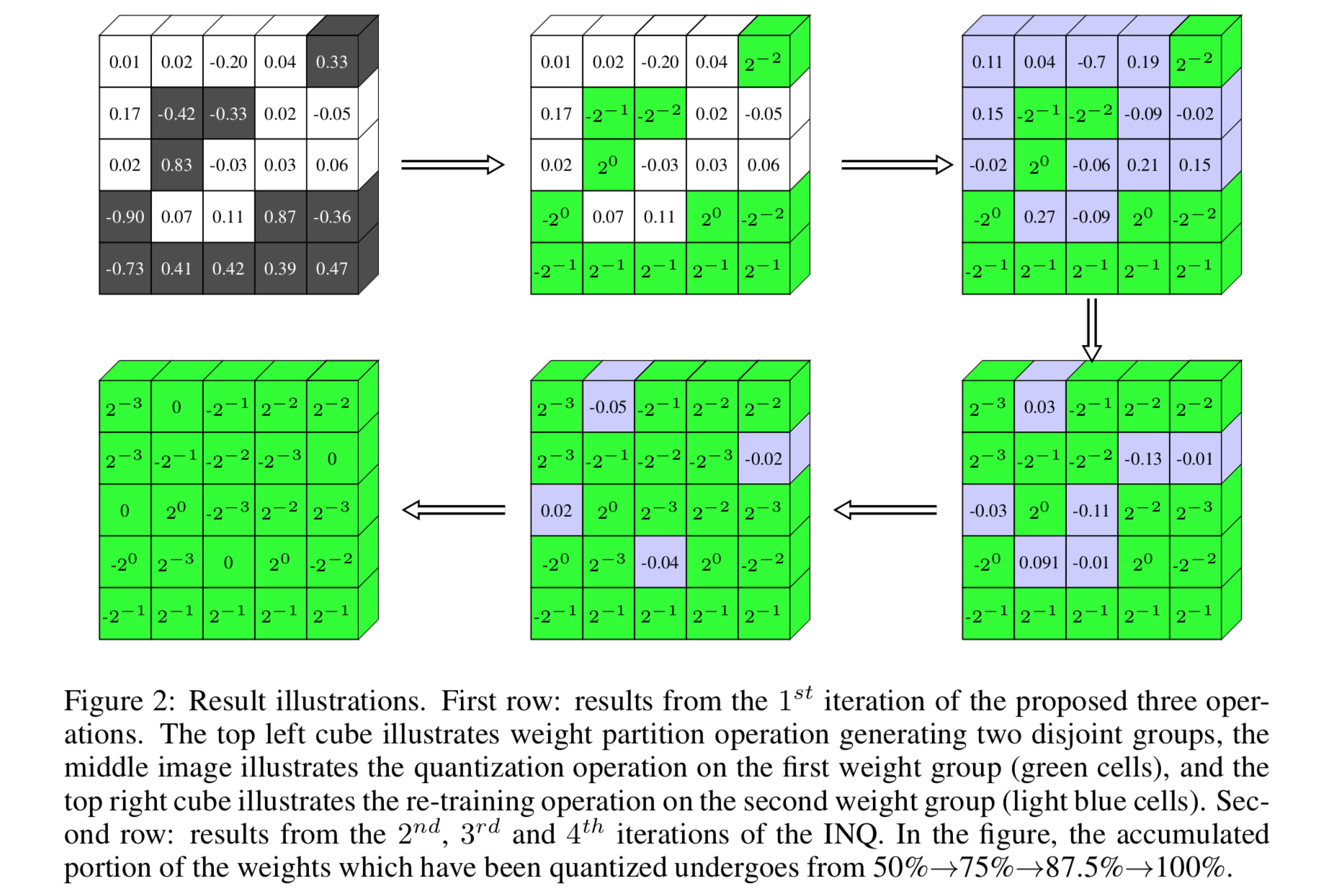
pruning-inspired strategy
在权重划分步骤,作者指出,随机地将权重量化,不如根据权重的幅值,优先量化那些绝对值比较大的权重。比较结果见下图。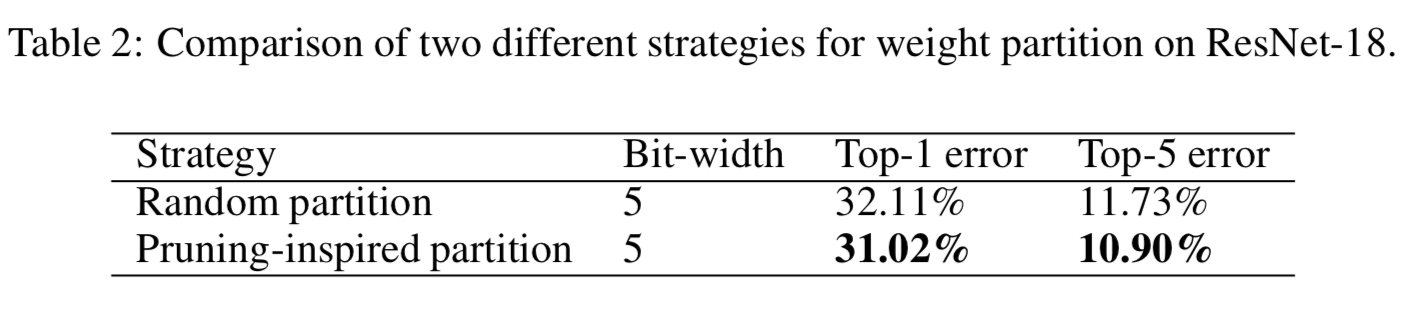
在代码部分,INQ基于Caffe框架,主要修改的地方集中于blob.cpp和sgd_solver.cpp中。量化部分的代码如下,首先根据要划分的比例计算出两个集合分界点处的权重大小。然后将大于该值的权重进行量化,小于该值的权重保持不变。下面的代码其实有点小问题,data_copy使用完之后没有释放。关于代码中mask的作用,下文介绍。
1 | // blob.cpp |
参数更新
在re-training中,我们只对未量化的那些参数进行更新。待更新的参数,mask中的值都是$1$,这样和diff相乘仍然不变;不更新的参数,mask中的值都是$0$,和diff乘起来,相当于强制把梯度变成了$0$。
1 | // sgd_solver.cpp |
结语
论文中还有一些其他的小细节,这里不再多说。本文的作者还维护了一个关于模型量化压缩相关的repo,也可以作为参考。