Visualizing & Understanding ConvNet这篇文章是比较早期关于CNN调试的文章,作者利用可视化方法,设计了一个超过AlexNet性能的网络结构。

引言
继AlexNet之后,CNN在ImageNet竞赛中得到了广泛应用。AlextNet成功的原因包括以下三点:
- Large data。
- 硬件GPU性能。
- 一些技巧提升了模型的泛化能力,如Dropout技术。
不过CNN仍然像一只黑盒子,缺少可解释性。这使得对CNN的调试变得比较困难。我们提出了一种思路,可以找出究竟input中的什么东西对应了激活后的Feature map。
(对于神经网络的可解释性,可以从基础理论入手,也可以从实践中的经验入手。本文作者实际上就是在探索如何能够更好得使用经验对CNN进行调试。这种方法仍然没有触及到CNN本质的可解释性的东西,不过仍然在工程实践中有很大的意义,相当于将黑盒子变成了灰盒子。从人工取火到炼金术到现代化学,也不是这么一个过程吗?)
在AlexNet中,每个卷积单元常常由以下几个部分组成:
- 卷积层,使用一组学习到的$3D$滤波器与输入(上一层的输出或网络输入的数据)做卷积操作。
- 非线性激活层,通常使用
ReLU(x) = max(0, x)。 - 可选的,池化层,缩小Feature map的尺寸。
- 可选的,LRN层(现在已经基本不使用)。
DeconvNet
我们使用DeconvNet这项技术,寻找与输出的激活对应的输入模式。这样,我们可以看到,输入中的哪个部分被神经元捕获,产生了较强的激活。
如图所示,展示了DeconvNet是如何构造的。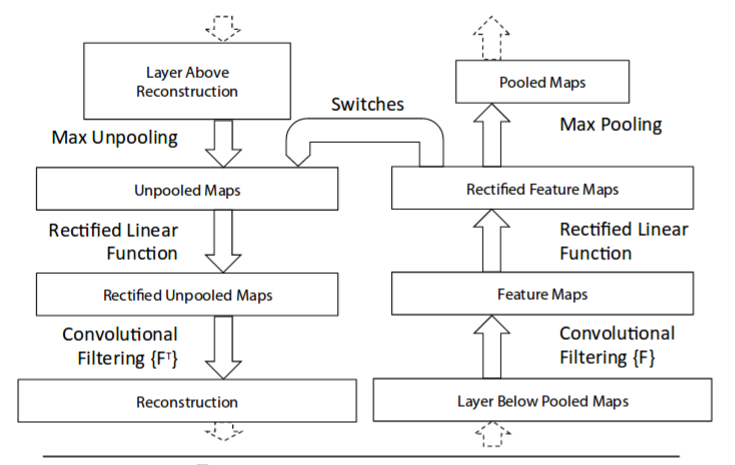
首先,图像被送入卷积网络中,得到输出的feature map。对于输出的某个激活,我们可以将其他激活值置成全$0$,然后顺着deconvNet计算,得到与之对应的输入。具体来说,我们需要对三种不同的layer进行反向操作。
Uppooling
在CNN中,max pooling操作是不可逆的(信息丢掉了)。我们可以使用近似操作:记录最大值的位置;在deconvNet中,保留该标记位置处的激活值。如下图所示。右侧为CNN中的max pooling操作。中间switches显示的是最大值的位置(用灰色标出)。在左侧的deconvNet中,激活值对应给到相应的灰色位置。这个操作被称为Uppooing。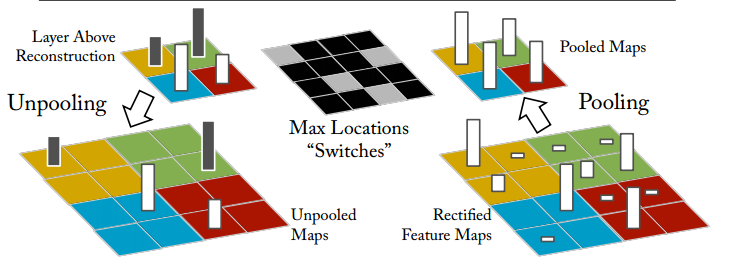
Rectification
在CNN中,一般使用relu作为非线性激活。deconvNet中也做同样的处理。
Filtering
在CNN中,一组待学习的filter用来与输入的feature map做卷积。得到输出。在deconvNet中,使用deconv操作,输入是整流之后的feature map。
对于最终输出的activation中的每个值,经过deconv的作用,最终会对应到输入pixel space上的一小块区域,显示了它们对最终输出的贡献。
CNN的可视化
要想可视化,先要有训练好的CNN模型。这里用作可视化的模型基于AlexNet,但是去掉了group。另外,为了可视化效果,将layer $1$的filter size从$11\times 11$变成$7\times 7$,步长变成$2$。具体训练过程不再详述。
训练完之后,我们将ImageNet的validation数据集送入到网络中进行前向计算,
如下所示,是layer $1$的可视化结果。可以看到,右下方的可视化结果被分成了$9\times 9$的方格,每个方格内又细分成了$9\times 9$的小格子。其中,大格子对应的是$9$个filter,小格子对应的是top 9的激活利用deconvNet反算回去对应的image patch、因为layer 1的filter个数正好也是$9$,所以可能稍显迷惑。
附录
这里是关于CNN可视化的一些额外资料:
- Zeiler关于本文的talk:Visualizing and Understanding Deep Neural Networks by Matt Zeiler
- 斯坦福CS231课程的讲义:Visualizing what ConvNets learn
- ICML 2015上的另一篇CNN可视化的paper:Understanding Neural Networks Through Deep Visualization以及他们的开源工具:deep-visualization-toolbox
- 一篇知乎专栏的文章:Deep Visualization:可视化并理解CNN