Residuel Net是MSRA HeKaiming组的作品,斩获了ImageNet挑战赛的所有项目的第一,并荣获CVPR的best paper,成为state of the ar的网络结构。这篇文章记录了阅读最初论文“Deep Residual Learning for Image Recongnition”的重点。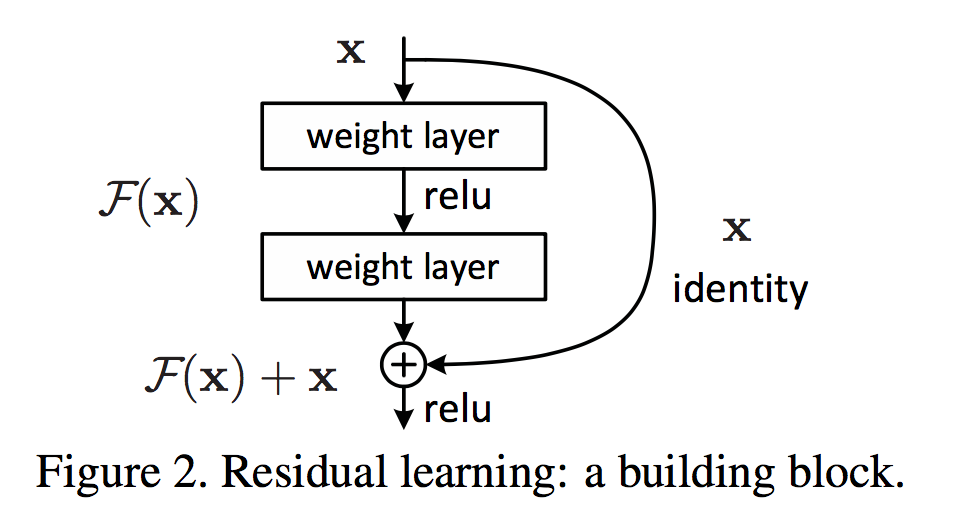
toy demo - PyTorch + MNIST
本篇文章介绍了使用PyTorch在MNIST数据集上训练MLP和CNN,并记录自己实现过程中的若干问题。
远程登录Jupyter笔记本
Jupyter Notebook可以很方便地记录代码和内容,很适合边写笔记边写示例代码进行学习总结。在本机使用时,只需在相应文件夹下使用jupyter notebook命令即可在浏览器中打开笔记页面,进行编辑。而本篇文章记述了如何在远端登录并使用Jupyter笔记本。这样,就可以利用服务器较强的运算能力来搞事情了。![]()
PyTorch简介
这是一份阅读PyTorch教程的笔记,记录jupyter notebook的关键点。原地址位于GitHub repo。![]()
在Caffe中使用Baidu warpctc实现CTC Loss的计算
CTC(Connectionist Temporal Classification) Loss 函数多用于序列有监督学习,优点是不需要对齐输入数据及标签。本文内容并不涉及CTC Loss的原理介绍,而是关于如何在Caffe中移植Baidu美研院实现的warp-ctc,并利用其实现一个LSTM + CTC Loss的验证码识别demo。下面这张图引用自warp-ctc的项目页面。本文介绍内容的相关代码可以参见我的GitHub项目warpctc-caffe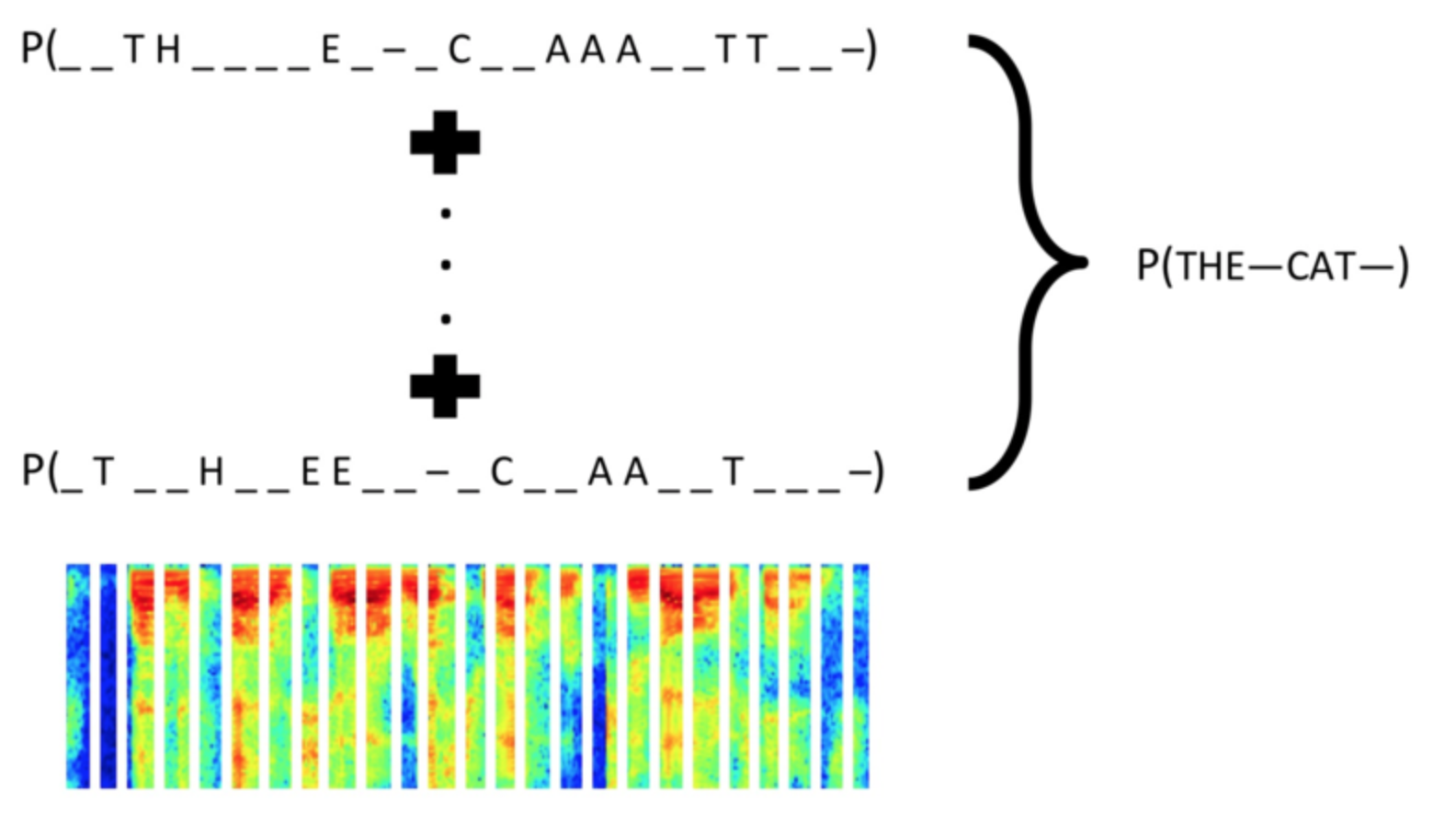
CS131-MeanShift
MeanShift最初由Fukunaga和Hostetler在1975年提出,但是一直到2000左右这篇PAMI的论文Mean Shift: A Robust Approach Toward Feature Space Analysis,将它的原理和收敛性等重新整理阐述,并应用于计算机视觉和图像处理领域之后,才逐渐为人熟知。
MeanShift是一种用来寻找特征空间内模态的方法。所谓模态(Mode),就是指数据集中最经常出现的数据。例如,连续随机变量概率密度函数的模态就是指函数的极大值。从概率的角度看,我们可以认为数据集(或者特征空间)内的数据点都是从某个概率分布中随机抽取出来的。这样,数据点越密集的地方就说明这里越有可能是密度函数的极大值。MeanShift就是一种能够从离散的抽样点中估计密度函数局部极大值的方法。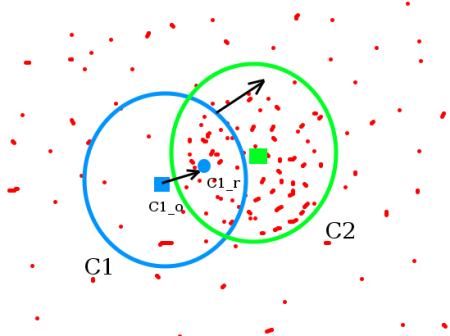
在Ubuntu14.04构建Caffe
Caffe作为较早的一款深度学习框架,很是流行。然而,由于依赖项众多,而且Jia Yangqing已经毕业,所以留下了不少的坑。这篇博客记录了我在一台操作系统为Ubuntu14.04.3的DELL游匣7559笔记本上编译Caffe的过程,主要是在编译python接口时遇到的import error问题的解决和找不到HDF5链接库的问题。

在DigitalOcean上配置Shadowsocks实现IPV4/IPV6翻墙
之前我使用GoAgent来FQ,后来又使用了一段时间的免费SS服务,后来机缘巧合从一个印度佬那里挣了一些美元,所以搬到了DigitalOcean上。DO的机器,对我一个学生来说,说实话并不算便宜了,不过好在手里还有一些美元,也在GitHub那里进行了学生认证,算是也可以应付了。
之前我已经在DO的机器上配置过shadowsocks,还顺手给iPad解决了FQ的问题。然而当时没有记录,这次我换了一台机器,机房位于NY,把ss重新配置了一遍,再不做些记录,下次恐怕又要东翻西找。
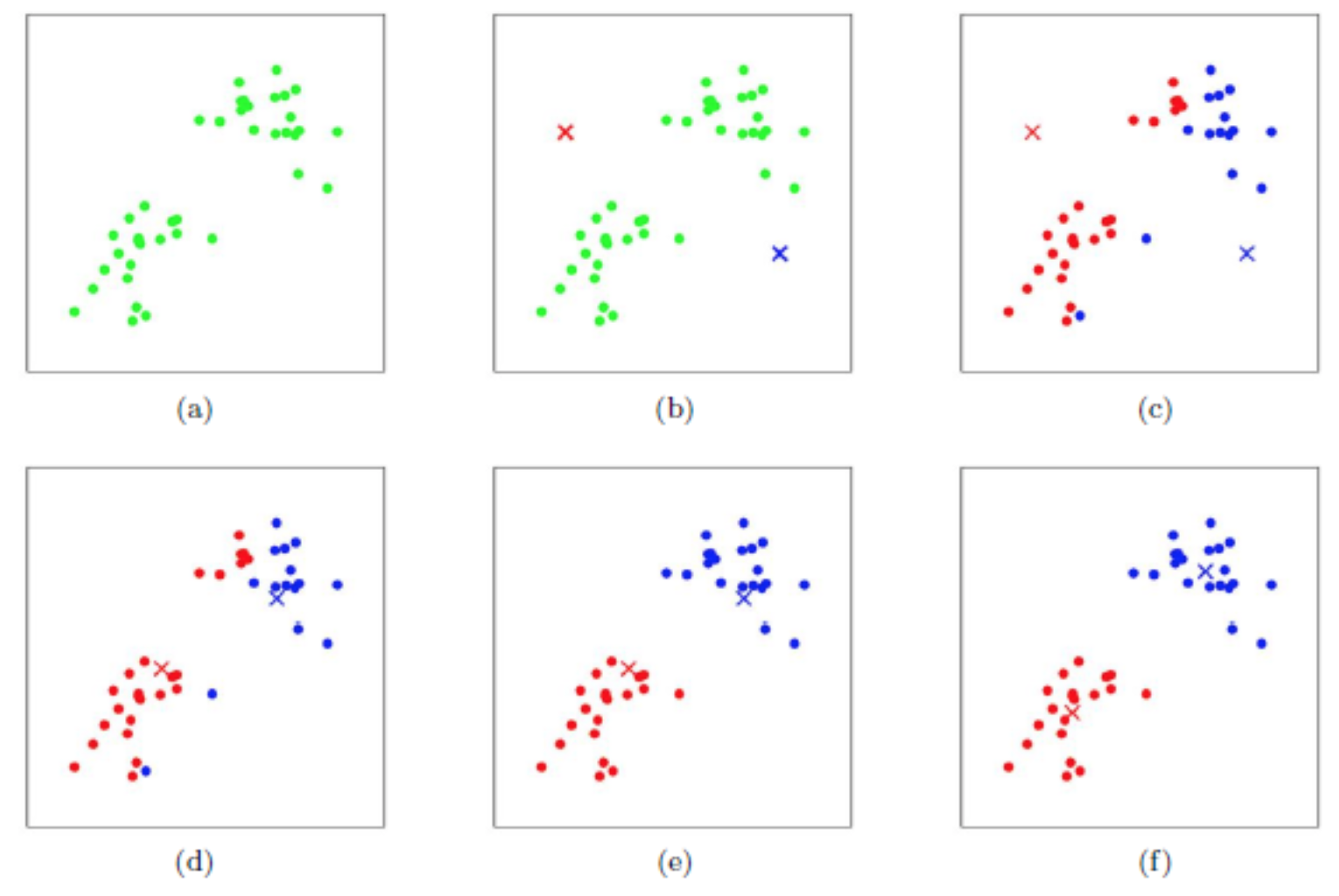
CS131-KMeans聚类
K-Means聚类是把n个点(可以是样本的一次观察或一个实例)划分到$k$个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准,满足最小化聚类中心和属于该中心的数据点之间的平方距离和(Sum of Square Distance,SSD)。
B站视频“线性代数的本质”观后感
线性代数对于现代科技的重要性不言而喻,在机器学习领域也是重要的工具。最近,在B站上发现了这样的一个视频:线性代数的本质。这个视频共有十集左右,每集大约10分钟,从线性空间入手,介绍线性变换,并由此介绍矩阵的相关性质,动画做的很棒,翻译得也很好,用了几天时间零散地把几集视频看完,记录一些心得。