SqueezeNet由HanSong等人提出,和AlexNet相比,用少于$50$倍的参数量,在ImageNet上实现了comparable的accuracy。比较本文和HanSoing其他的工作,可以看出,其他工作,如Deep Compression是对已有的网络进行压缩,减小模型size;而SqueezeNet是从网络设计入手,从设计之初就考虑如何使用较少的参数实现较好的性能。可以说是模型压缩的两个不同思路。
模型压缩相关工作
模型压缩的好处主要有以下几点:
- 更好的分布式训练。server之间的通信往往限制了分布式训练的提速比例,较少的网络参数能够降低对server间通信需求。
- 云端向终端的部署,需要更低的带宽,例如手机app更新或无人车的软件包更新。
- 更易于在FPGA等硬件上部署,因为它们往往都有着非常受限的片上RAM。
相关工作主要有两个方向,即模型压缩和模型结构自身探索。
模型压缩方面的工作主要有,使用SVD分解,Deep Compression等。模型结构方面比较有意义的工作是GoogLeNet的Inception module(可在博客内搜索Xception查看Xception的作者是如何受此启发发明Xception结构的)。
本文的作者从网络设计角度出发,提出了名为SqueezeNet的网络结构,使用比AlexNet少$50$倍的参数,在ImageNet上取得了comparable的结果。此外,还探究了CNN的arch是如何影响model size和最终的accuracy的。主要从两个方面进行了探索,分别是CNN microarch和CNN macroarch。前者意为在更小的粒度上,如每一层的layer怎么设计,来考察;后者是在更为宏观的角度,如一个CNN中的不同layer该如何组织来考察。
PS: 吐槽:看完之后觉得基本没探索出什么太有用的可以迁移到其他地方的规律。。。只是比较了自己的SqueezeNet在不同参数下的性能,有些标题党之嫌,题目很大,但是里面的内容并不完全是这样。CNN的设计还是实验实验再实验。
SqueezeNet
为了简单,下文简称SNet。SNet的基本组成是叫做Fire的module。我们知道,对于一个CONV layer,它的参数数量计算应该是:$K \times K \times M \times N$。其中,$K$是filter的spatial size,$M$和$N$分别是输入feature map和输出activation的channel size。由此,设计SNet时,作者的依据主要是以下几点:
- 把$3\times 3$的卷积替换成$1\times 1$,相当于减小上式中的$K$。
- 减少$3\times 3$filter对应的输入feature map的channel,相当于减少上式的$M$。
- delayed downsample。使得activation的feature map能够足够大,这样对提高accuracy有益。CNN中的downsample主要是通过CONV layer或pooling layer中stride设置大于$1$得到的,作者指出,应将这种操作尽量后移。
Our intuition is that large activation maps (due to delayed downsampling) can lead to higher classification accuracy, with all else held equal.
Fire Module
Fire Module是SNet的基本组成单元,如下图所示。可以分为两个部分,一个是上面的squeeze部分,是一组$1\times 1$的卷积,用来将输入的channel squeeze到一个较小的值。后面是expand部分,由$1\times 1$和$3\times 3$卷积mix起来。使用$s_{1 x 1}$,$e_{1x1}$和$e_{3x3}$表示squeeze和expand中两种不同卷积的channel数量,令$s_{1x1} < e_{1x1} + e_{3x3}$,用来实现上述策略2.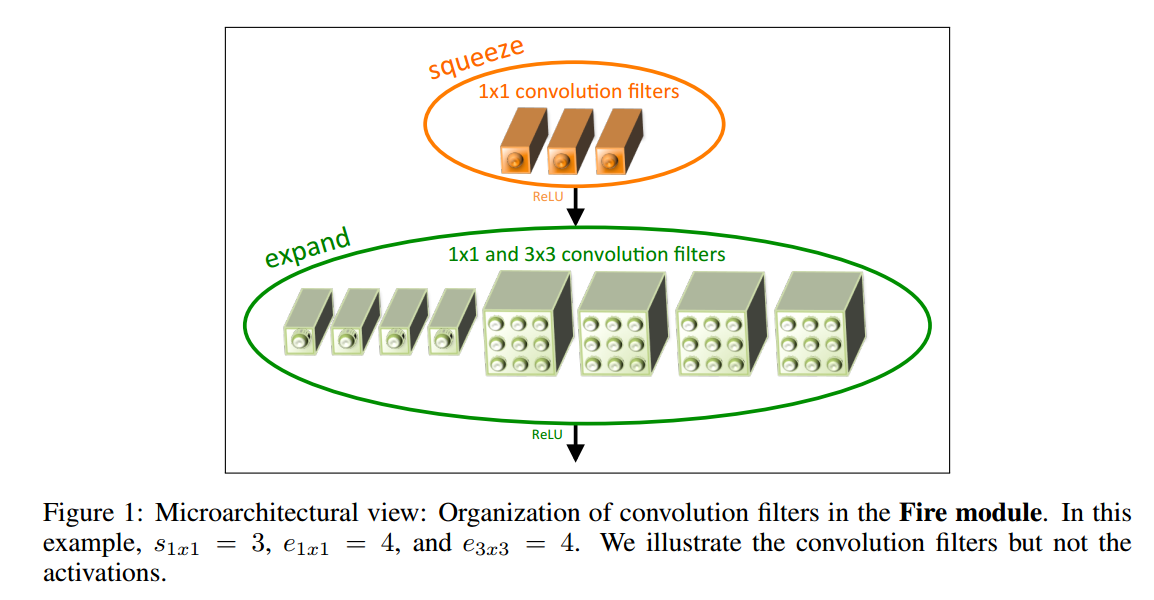
下面,对照PyTorch实现的SNet代码看下Fire的实现,注意上面说的CONV后面都接了ReLU。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
## squeeze 部分
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
## expand 1x1 部分
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
## expand 3x3部分
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
## 将expand 部分1x1和3x3的cat到一起
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))], 1)
SNet
有了Fire Module这个基础材料,我们就可以搭建SNet了。一个单独的conv1 layer,后面接了$8$个连续的Fire Module,最后再接一个conv10 layer。此外,在conv1,fire4, fire8和conv10后面各有一个stride=2的MAX Pooling layer。这些pooling的位置相对靠后,是对上述策略$3$的实践。我们还可以在不同的Fire Module中加入ResNet中的bypass结构。这样,形成了下图三种不同的SNet结构。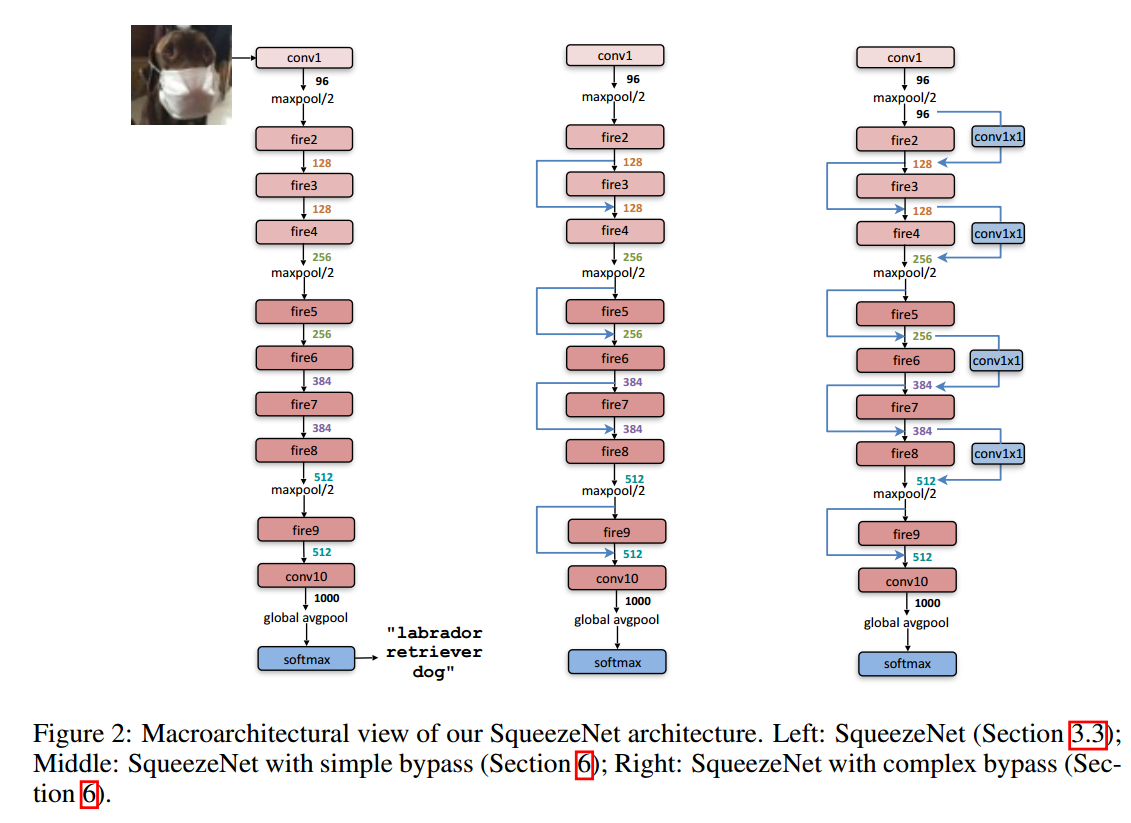
一些细节:
- 为了使得$1\times 1$和$3\times 3$的卷积核能够有相同spatial size的输出,$3\times 3$的卷积输入加了
padding=1。 - 在squeeze layer和expand layer中加入了ReLU。
- 在
fire 9后加入了drop ratio为$0.5$的Dropout layer。 - 受NIN启发,SNet中没有fc层。
- 更多的细节和训练参数的设置可以参考GitHub上的官方repo。
同样的,我们可以参考PyTorch中的实现。注意下面实现了v1.0和v1.1版本,两者略有不同。v1.1版本参数更少,也能够达到v1.0的精度。
SqueezeNet v1.1 (in this repo), which requires 2.4x less computation than SqueezeNet v1.0 without diminshing accuracy.
1 | class SqueezeNet(nn.Module): |
实验
把SNet和AlexNet分别经过Deep Compression,在ImageNet上测试结果如下。可以看到,未被压缩时,SNet比AlexNet少了$50$倍,accuracy是差不多的。经过压缩,SNet更是可以进一步瘦身成不到$0.5$M,比原始的AlexNet瘦身了$500+$倍。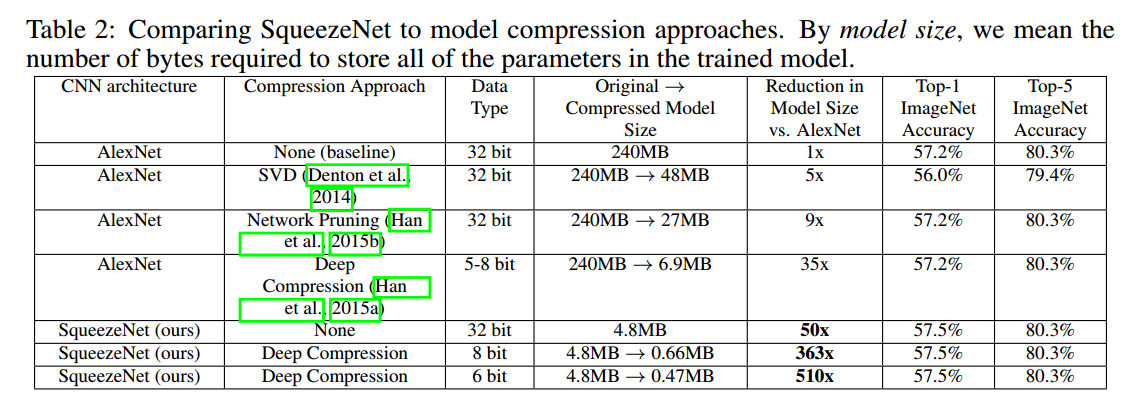
注意上述结果是使用HanSong的Deep Compression技术(聚类+codebook)得到的。这种方法得到的模型在通用计算平台(CPU/GPU)上的优势并不明显,需要在作者提出的EIE硬件上才能充分发挥其性能。对于线性的量化(直接用量化后的$8$位定点存储模型),Ristretto实现了SNet的量化,但是有一个点的损失。
Micro Arch探索
所谓CNN的Micro Arch,是指如何确定各层的参数,如filter的个数,kernel size的大小等。在SNet中,主要是filter的个数,即上文提到的$s_{1x1}$,$e_{1x1}$和$e_{3x3}$。这样,$8$个Fire Module就有$24$个超参数,数量太多,我们需要加一些约束,暴露主要矛盾,把问题变简单一点。
我们设定$base_e$是第一个Fire Module的expand layer的filter个数,每隔$freq$个Fire Module,会加上$incr_e$这么多。那么任意一个Fire Module的expand layer filter的个数为$e_i = base_e + (incr_e \times \lfloor \frac{i}{freq}\rfloor)$。
在expand layer,我们有$e_i = e_{i,1x1} + e_{i,3x3}$,设定$pct_{3x3} = e_{i,3x3}/e_i$为$3\times 3$的conv占的比例。
设定$SR = s_{i,1x1} / e_i$,为squeeze和expand filter个数比例。
SR的影响
$SR$于区间$[0.125, 1]$之间取,accuracy基本随着$SR$增大而提升,同时模型的size也在变大。但$SR$从$0.75$提升到$1.0$,accuracy无提升。publish的SNet使用了$SR=0.125$。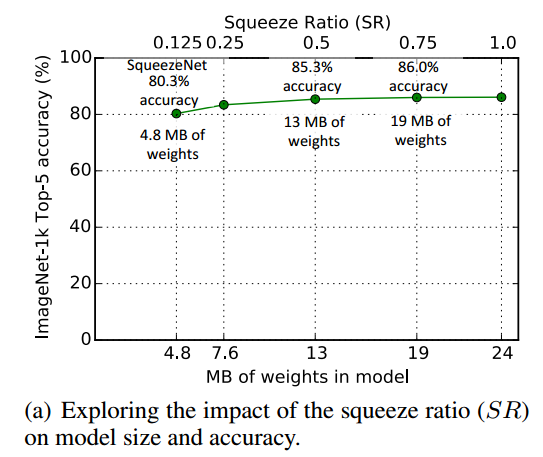
1X1和3x3的比例pct的影响
为了减少参数,我们把部分$3\times 3$的卷积换成了$1\times 1$的,构成了expand layer。那么两者的比例对模型的影响?$pct$在$[0.01, 0.99]$之间变化。同样,accuracy和model size基本都随着$pct$增大而提升。当大于$0.5$时,模型的accuracy基本无提升。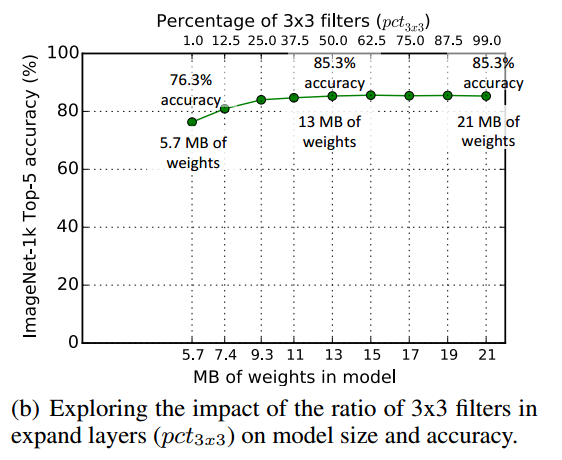
Macro Arch探索
这里主要讨论了是否使用ResNet中的bypass结构。