在MXNet中,Module提供了训练模型的方便接口。使用symbol将计算图建好之后,用Module包装一下,就可以通过fit()方法对其进行训练。当然,官方提供的接口一般只适合用来训练分类任务,如果是其他任务(如detection, segmentation等),单纯使用fit()接口就不太合适。这里把fit()代码梳理一下,也是为了后续方便在其基础上实现扩展,更好地用在自己的任务。
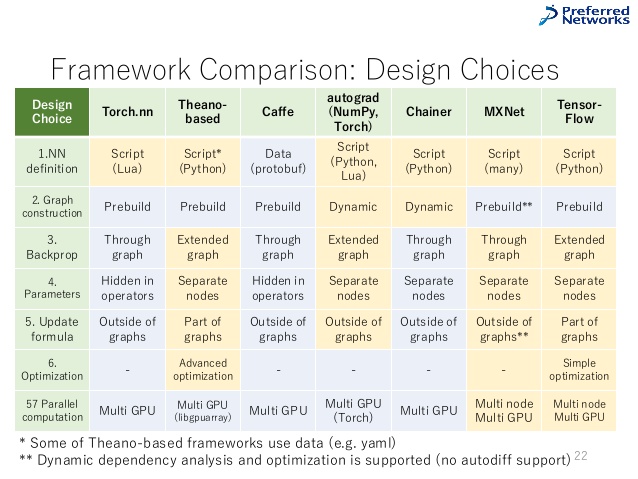
其实如果看开源代码数量的话,MXNet已经显得式微,远不如TensorFlow,PyTorch也早已经后来居上。不过据了解,很多公司内部都有基于MXNet自研的框架或平台工具。下面这张图来自LinkedIn上的一个Slide分享,姑且把它贴在下面,算是当前流行框架的一个比较(应该可以把Torch换成PyTorch)。